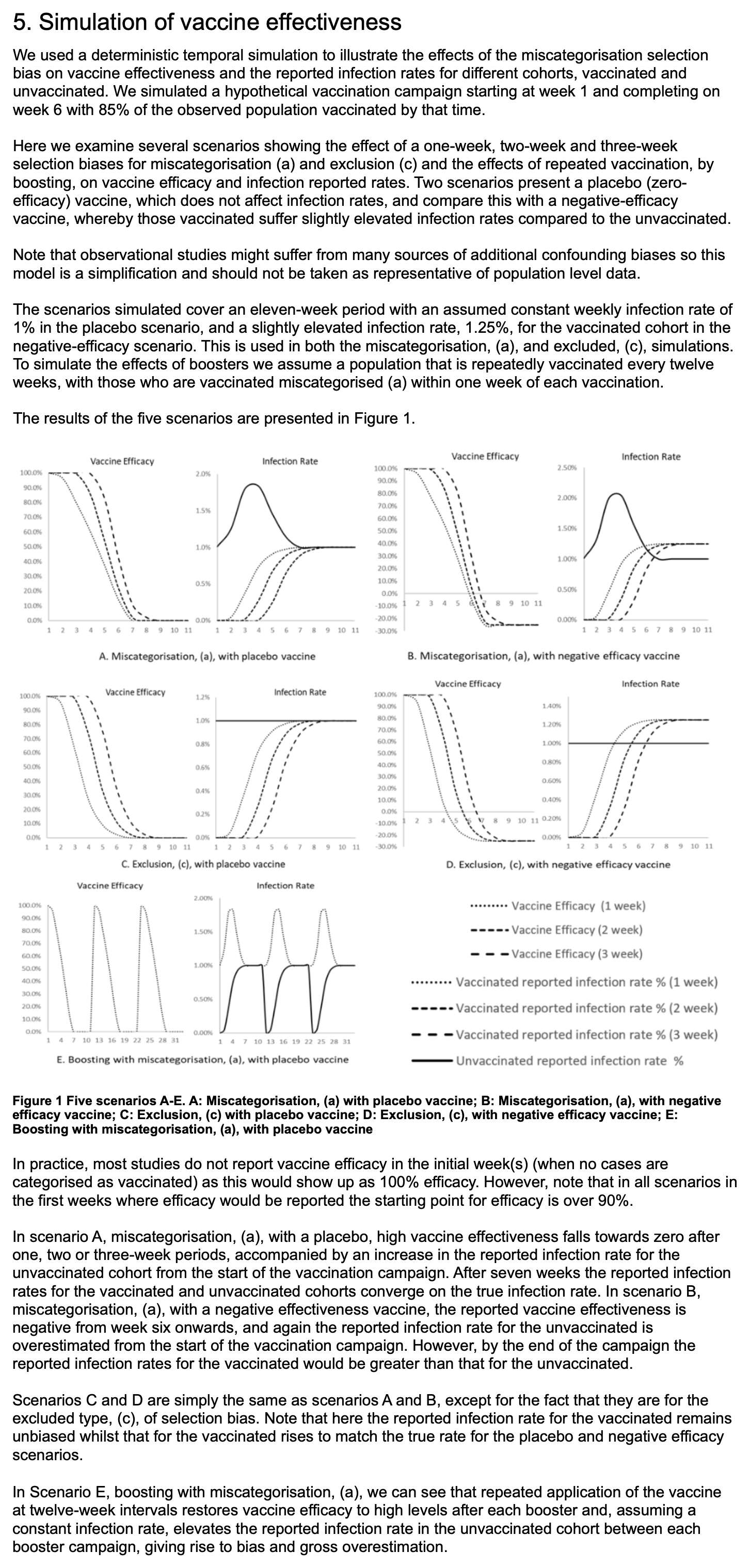
In March 2024, Martin Neil, Norman Fenton, and Scott McLachlan
published a preprint titled "The extent and impact
of vaccine status miscategorisation on covid-19 vaccine efficacy
studies". [https://
Note how they relied on a simulation to demonstrate that the cheap trick would increase vaccine efficacy.
The methodology they used to do the simulations was poorly described, because for example they didn't mention that they only applied the cheap trick to the numerator but not to the denominator, and they didn't explain which number of new vaccine doses they simulated on each day or week of the simulation. And they didn't even explain why unvaccinated people only had one line in their plots, even though there should've been three different lines that would've corresponded to the three lines for vaccinated people. And at first I even thought that the weeks in their simulation were weeks since vaccination, but actually they were weeks of the simulation instead. This shows the results of the simulation:
For example in scenario A, the vaccine was supposed to be a placebo
which had no effect on the infection rate, and all people had a 1%
constant infection rate regardless of whether they were vaccinated or
not. So I thought that even if people would be classified as
unvaccinated for the first 1 to 3 weeks after vaccination, both
unvaccinated and vaccinated people should still have a constant
infection rate of 1%. But I only understood how the model worked after
Uncle John Returns posted this tweet: [https://
I've simulated Fenton's simulation. I've only shown the 1 week unvaccinated line (to hit 1% in week 7). You can get almost any shape you like by adjusting the vaccinations per week. Curves smoothed by Excel.

I reproduced Uncle John's plot, but I didn't add the smoothing, and I also added lines for unvaccinated people in the scenarios where people were considered as unvaccinated for 2 or 3 weeks after vaccination:
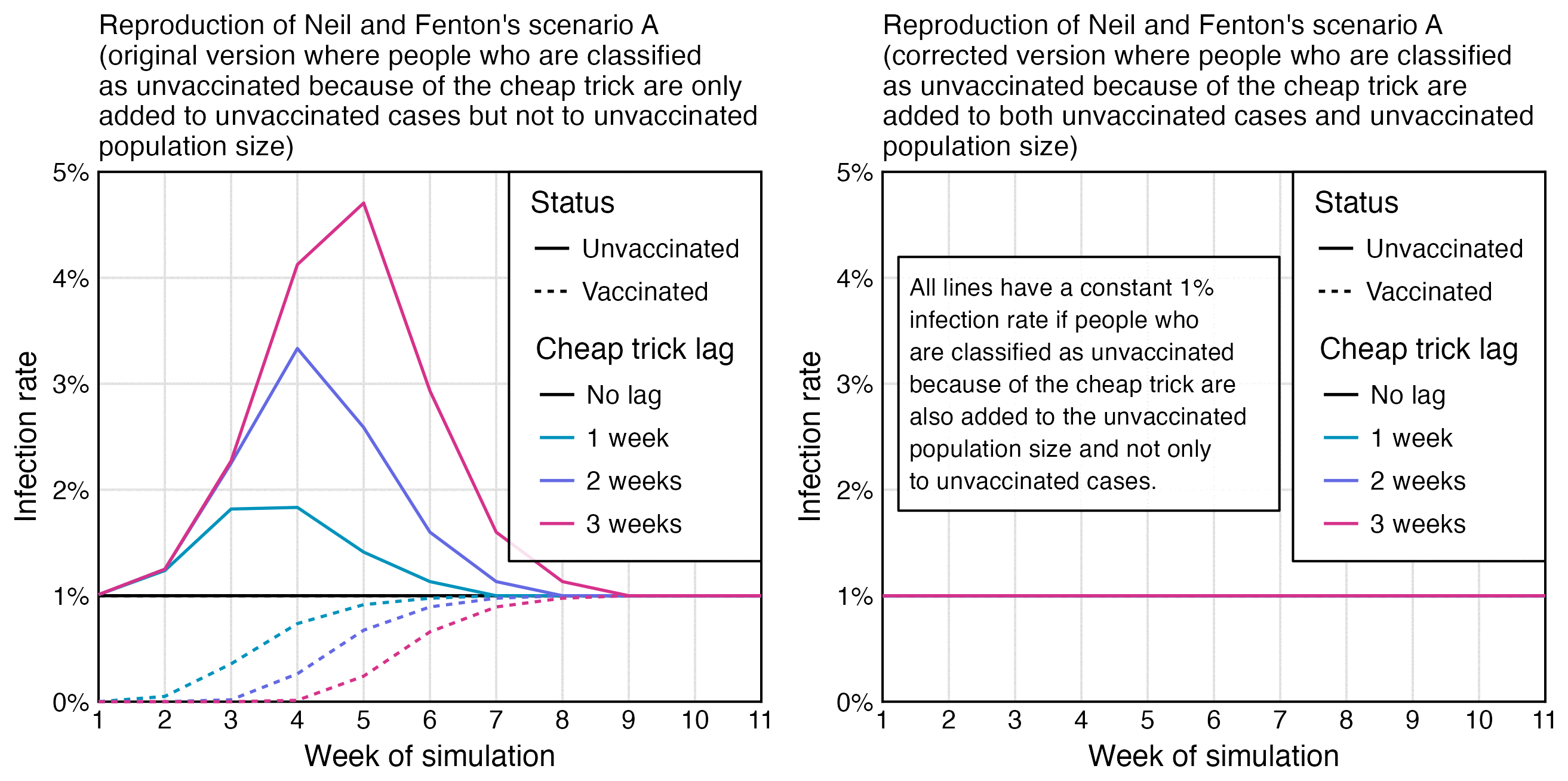
library(ggplot2) weeks=11 vax=cumsum( c( 10, 190, 360, 200, 70, 20, rep( 0, 5))) lv=c( " No lag", " 1 week", " 2 weeks", " 3 weeks") lag=factor( rep( lv, each=weeks), lv) lagged=embed( c( rep( 0, 3), vax), 4) xy=data. frame( x=1: weeks, y=c( 1000- lagged)/ c( 1000- vax), lag, status=" Unvaccinated") xy=rbind( xy, data. frame( x=1: weeks, y=c( lagged)/ vax, lag, status=" Vaccinated")) # xy=data. #frame( x=1: weeks, y=1, lag, status=" Unvaccinated") xy=rbind( xstart=1;xy, data. frame( x=1: weeks, y=1, lag, status=" Vaccinated")) xend=weeks; ystart=0; yend=5 pal=c( " black", hcl( c( 200, 250, 330)+ 15, 100, 50)) ggplot( xy, aes( x, y))+ geom_ hline( yintercept=c( ystart, yend), linewidth=. 3, lineend=" square")+ geom_ vline( xintercept=c( xstart, xend), linewidth=. 3, lineend=" square")+ geom_ line( aes( color=lag, linetype=status), linewidth=. 4)+ # annotate( #geom=" label", fill=alpha( " white",. 8), x=1. 24, y=3, hjust=0, vjust=. 5, label=paste0( " All lines have a constant 1% infection rate if people who are classified as unvaccinated because of the cheap trick are also added to the unvaccinated population size and not only to unvaccinated cases. ")| fw( 30), size=2. 3, label. r=unit( 0, " lines"), label. padding=unit(. 4, " lines"), label. size=. 3, lineheight=1. 1)+ labs( labs(title=" Reproduction of Neil and Fenton' s scenario A (corrected version where people who are classified as unvaccinated because of the cheap trick are added to both unvaccinated cases and unvaccinated population size) "| > stringr:: str_ wrap( 52), x=" Week of simulation", y=" Infection rate")+ title=" Reproduction of Neil and Fenton' s scenario A (original version where people who are classified as unvaccinated because of the cheap trick are only added to unvaccinated cases but not to unvaccinated population size) "| > stringr:: str_ wrap( 52), x=" Week of simulation", y=" Infection rate")+ scale_ x_ continuous( limits=c( xstart, xend), breaks=seq( xstart, xend))+ scale_ y_ continuous( limits=c( ystart, yend), breaks=seq( ystart, yend), labels=\( x) paste0( x, "% "))+ coord_ cartesian( clip=" off", expand=F)+ scale_ color_ manual( values=pal)+ guides( linetype=guide_ legend( title=" Status"), color=guide_ legend( title=" Cheap trick lag"))+ theme( axis. text=element_ text( size=7, color=" black"), axis. ticks=element_ blank(), axis. ticks. length=unit( 0, " lines"), axis. title=element_ text( size=8), legend. background=element_ blank(), legend. box. background=element_ rect( fill=alpha( " white",. 85), color=" black", linewidth=. 3), legend. box. just=" center", legend. direction=" vertical", legend. justification=c( 1, 1), legend. key=element_ rect( fill=alpha( " white", 0)), legend. key. size=unit(. 8, " lines"), legend. margin=margin(. 3,. 4,. 3,. 4, " lines"), legend. position=c( 1, 1), legend. spacing. x=unit(. 15, " lines"), legend. spacing. y=unit(-. 2, " lines"), legend. text=element_ text( size=7, vjust=. 5), legend. title=element_ text( size=8, margin=margin(
