Sections about UK statistics have been moved here:
uk.
Fabian Spieker published a Substack post where he presented the
hypothesis that many of the COVID deaths in summer 2021 in the United
States were caused by "vaccine-medicated enhanced
disease", since in the southeastern states which had a massive
wave of COVID deaths in the summer of 2021, many people who had
previously not been vaccinated were getting their first vaccine dose
around the same time. [https://
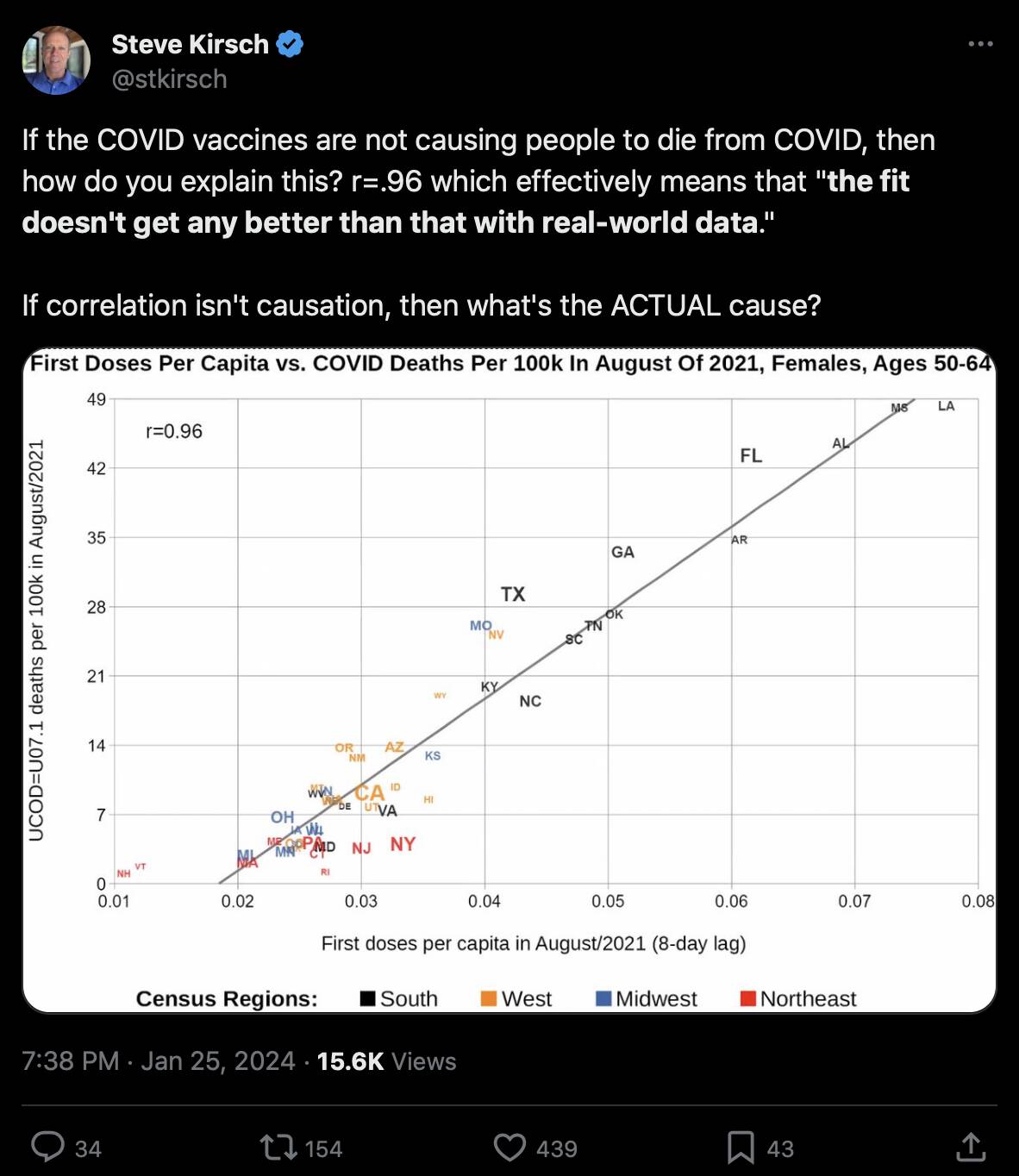
Kirsch posted this tweet: [https://
However the states where people were still getting first shots in August 2021 tended to have a low percentage of vaccinated people. I got a correlation of about -0.55 when I included all ages and all sexes and I looked at the percentage of vaccinated people in August 2021 and not the percentage of people who got the first shot in August 2021:
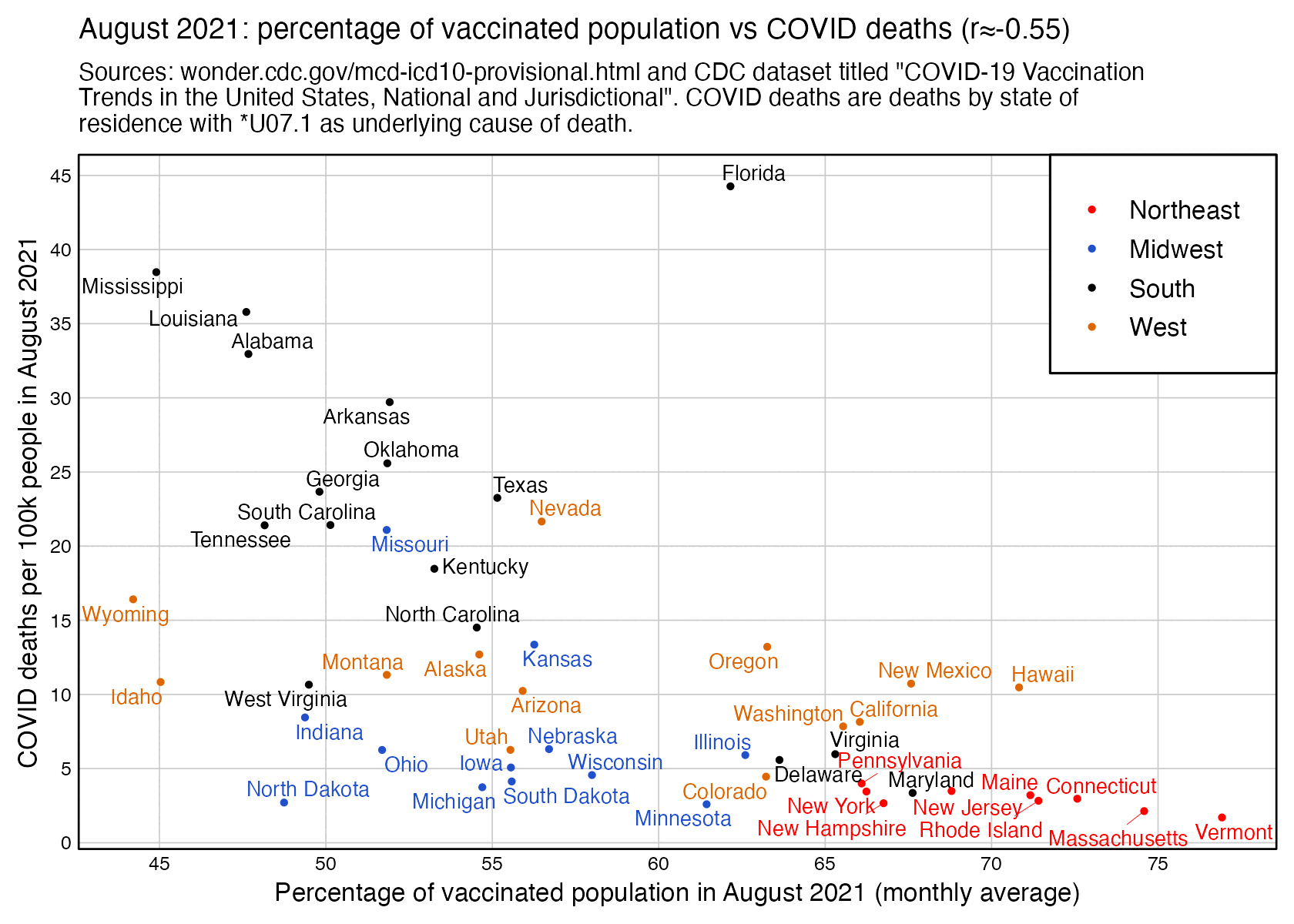
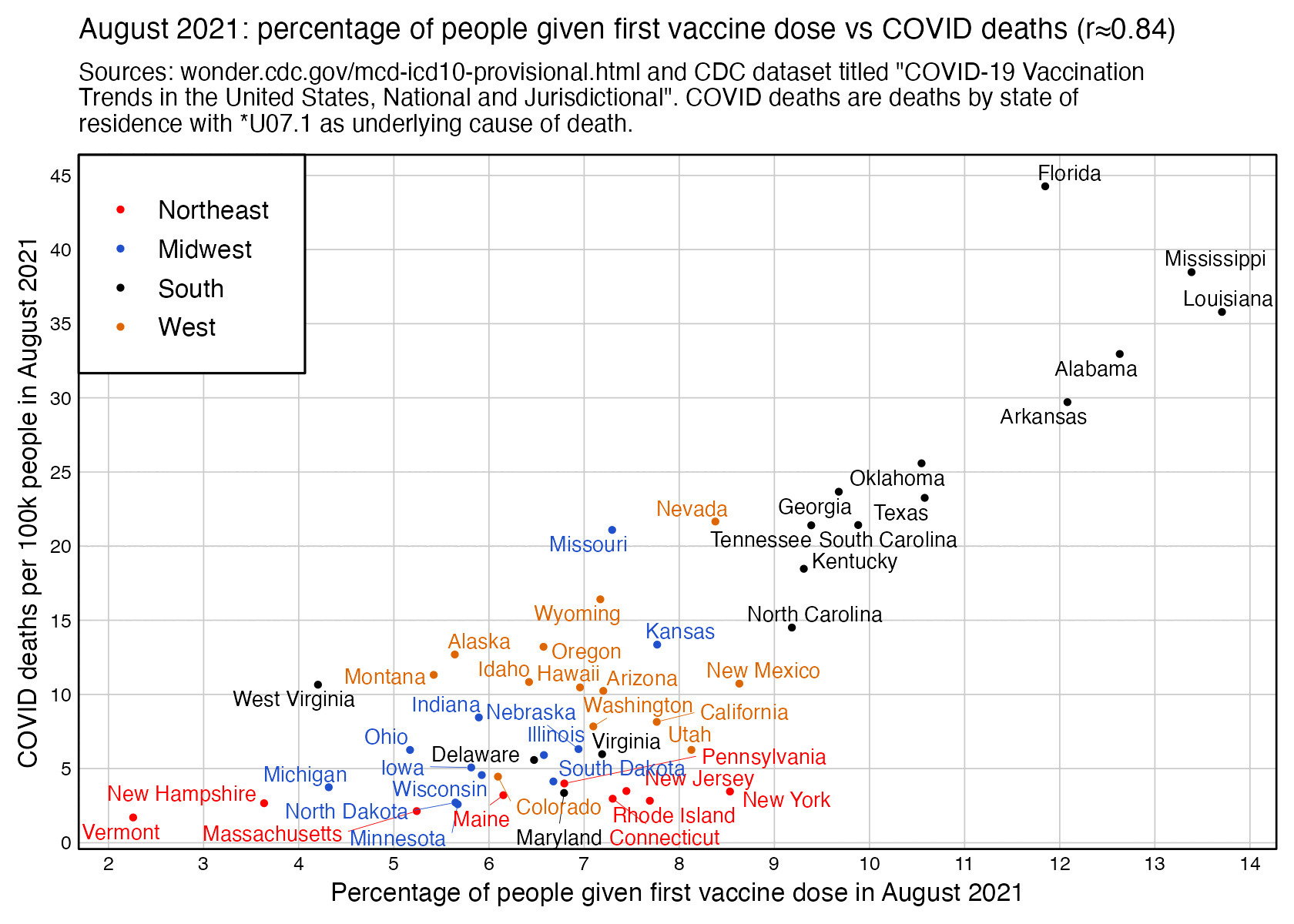
In the southeastern states which had the highest number of COVID deaths per capita in August 2021, there was also a spike in PCR positivity rate which slightly preceded the deaths:
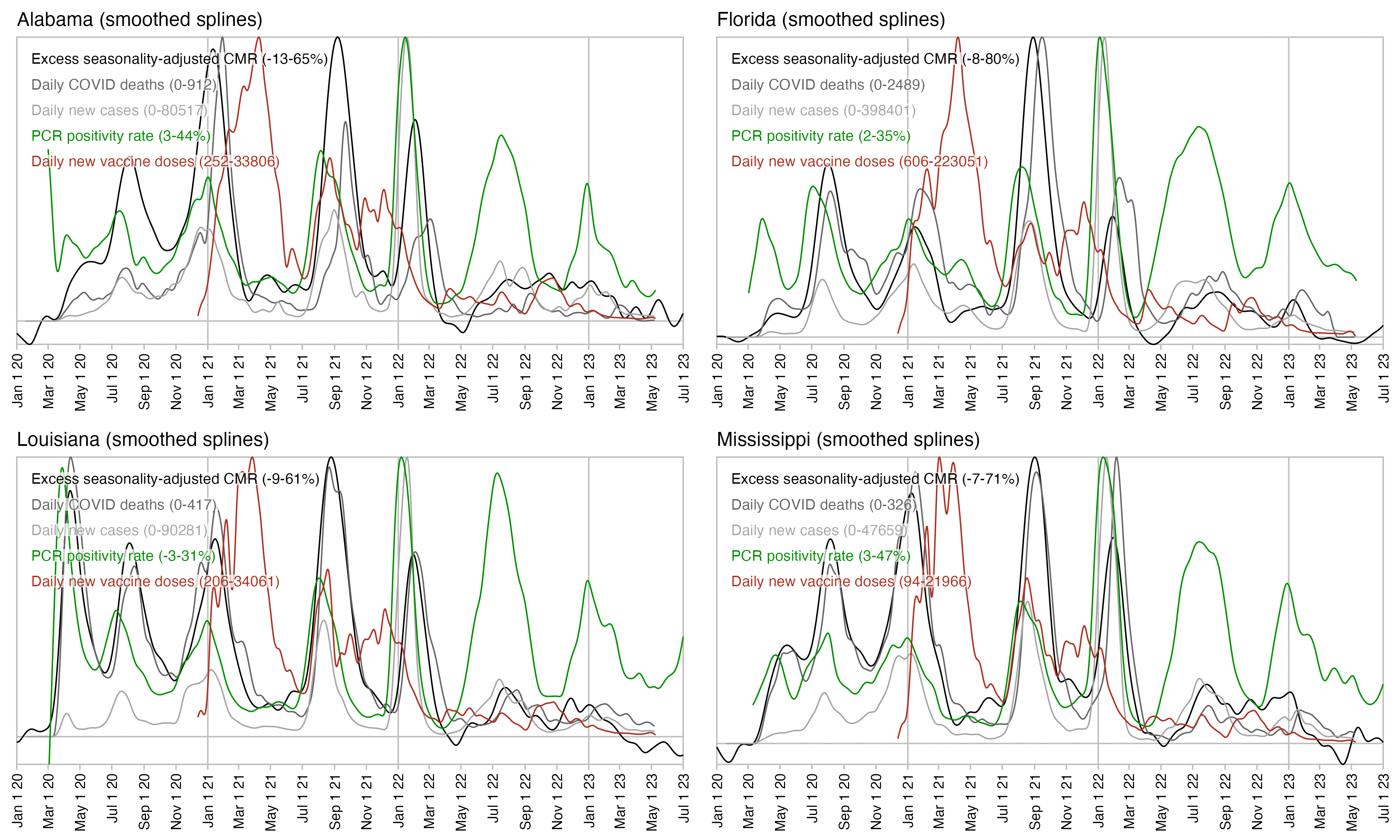
In fact the plot above shows that the spike in PCR positivity was short-lived like the spike in excess deaths, so both PCR positivity and excess deaths had fallen back near zero around November 2021, even though the daily number of new vaccine doses remained elevated until around March 2022. So the excess deaths not only rose in sync with PCR positivity rate but they also fell in sync after the PCR positivity rate fell down. And the same thing happened again during the Omicron wave.
In Florida there is only a small peak in vaccine doses around August 2021 when deaths peaked, and new vaccine doses remained around the same level until the end of 2021. But there was a sharp drop in PCR positivity rate which was followed by a sharp drop in excess mortality:
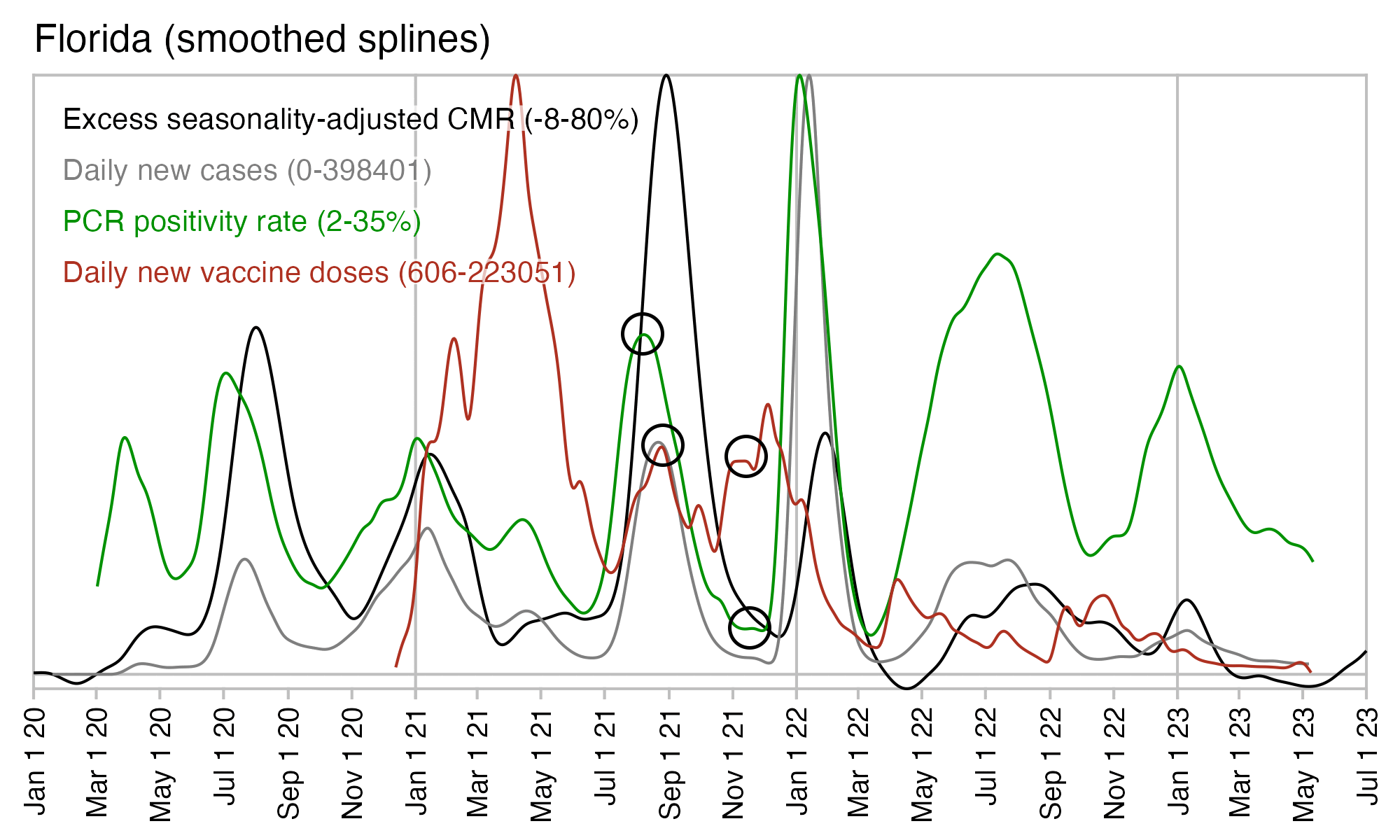
In February 2023 Kirsch published a spreadsheet of data from
Medicare, which includes the dates of vaccination and dates of death of
about 110,000 vaccinated people who died between December 2020 and
January 2023: [https://
$curl -Ls sars2. net/ f/ kirsch_ medicare_ all_ states_ subset. csv| head state, date_ of_ vaccination, date_ of_ death, age_ at_ death MI, 2020- 12- 16, 2020- 12- 20, 74 WI, 2020- 12- 16, 2021- 02- 16, 79 ME, 2020- 12- 16, 2021- 05- 18, 77 WI, 2020- 12- 16, 2021- 10- 24, 75 MN, 2020- 12- 16, 2021- 11- 24, 76 MI, 2020- 12- 16, 2021- 12- 06, 77 MI, 2020- 12- 16, 2022- 01- 24, 60 IN, 2020- 12- 16, 2022- 01- 28, 73 MI, 2020- 12- 16, 2022- 11- 08, 71
Compared to the total US population which also includes unvaccinated people, the vaccinated people who are included in the Medicare spreadsheet have reduced mortality during the Omicron wave in January 2022 and the Delta wave in August to September 2021, and in fact the bump in deaths during the Delta wave seems to be almost flat among the vaccinated people:

If you only look at ages 15-44 in Kirsch's Medicare spreadsheet, the sample size is so small that it's diffficult to tell if there's actually an increase in deaths in August 2021 or not:

In the Medicare data there's also a reduced number of deaths in the first weeks following a vaccination. For example in people who were vaccinated in August 2021, there's only 9 deaths during the first week from vaccination and 11 deaths the next week, but during later weeks the average number of deaths is about 25:
>med=read. csv( " https:// sars2. net/ f/ kirsch_ medicare_ all_ states_ subset. csv") > med[, 2] =as. Date( med[, 2]); med[, 3] =as. Date( med[, 3]) > weeks=with( subset( med, grepl( " 2021- 08", date_ of_ vaccination)), as. numeric( date_ of_ death- date_ of_ vaccination)%/% 7) > weeks=table( factor( weeks, min( weeks): max( weeks))) > weeks 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 9 11 31 36 19 26 24 26 29 24 39 23 22 24 27 28 28 35 28 28 39 32 22 18 32 30 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 32 27 30 25 23 24 18 24 14 20 21 31 26 28 24 24 21 21 20 17 26 23 23 21 27 17 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 24 15 20 23 18 22 29 12 18 21 20 19 19 21 30 25 25 26 21 27 22 15 15 14 4 > mean( weeks[ 3: 54]) [ 1] 25. 30769
And if you only look at the 5 southeastern states that had the highest number of COVID deaths per capita in August 2021, among people who were vaccinated in July to September 2021, there were only 3 deaths on the first week after vaccination and 5 deaths on the second week, even though the average number of deaths per week was later about 11:
>sub=subset( med, date_ of_ vaccination> =" 2021- 07- 01" & date_ of_ vaccination< =" 2021- 09- 30" & state% in% c( " AL", " AR", " FL", " LA", " MS")) > weeks=as. numeric( sub$ date_ of_ death- sub$ date_ of_ vaccination)%/% 7 > weeks=table( factor( weeks, min( weeks): max( weeks))) > weeks 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 3 5 12 17 11 8 10 6 9 8 9 9 9 12 15 14 14 13 16 8 13 11 13 18 9 12 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 11 14 10 19 12 12 15 8 10 9 12 8 11 7 10 4 13 11 12 8 9 8 12 9 13 11 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 7 10 10 8 11 9 12 9 10 9 5 9 8 11 20 9 8 10 9 8 10 5 4 3 3 3 78 79 2 2 > mean( weeks[ 3: 54]) [ 1] 10. 98077
In the Medicare "all states subset" sheet, if you look at the five southeastern states which had the highest number of COVID deaths per capita in August 2021, there's a low number of all-cause deaths in recently vaccinated people in July and August 2021. Among people who were vaccinated in August, there's only 6 deaths in August even though the average date of vaccination was on August 16th so August consists of roughly half a month, and the average number of deaths on subsequent months was about 17.5 which is almost 3 times higher than 6:
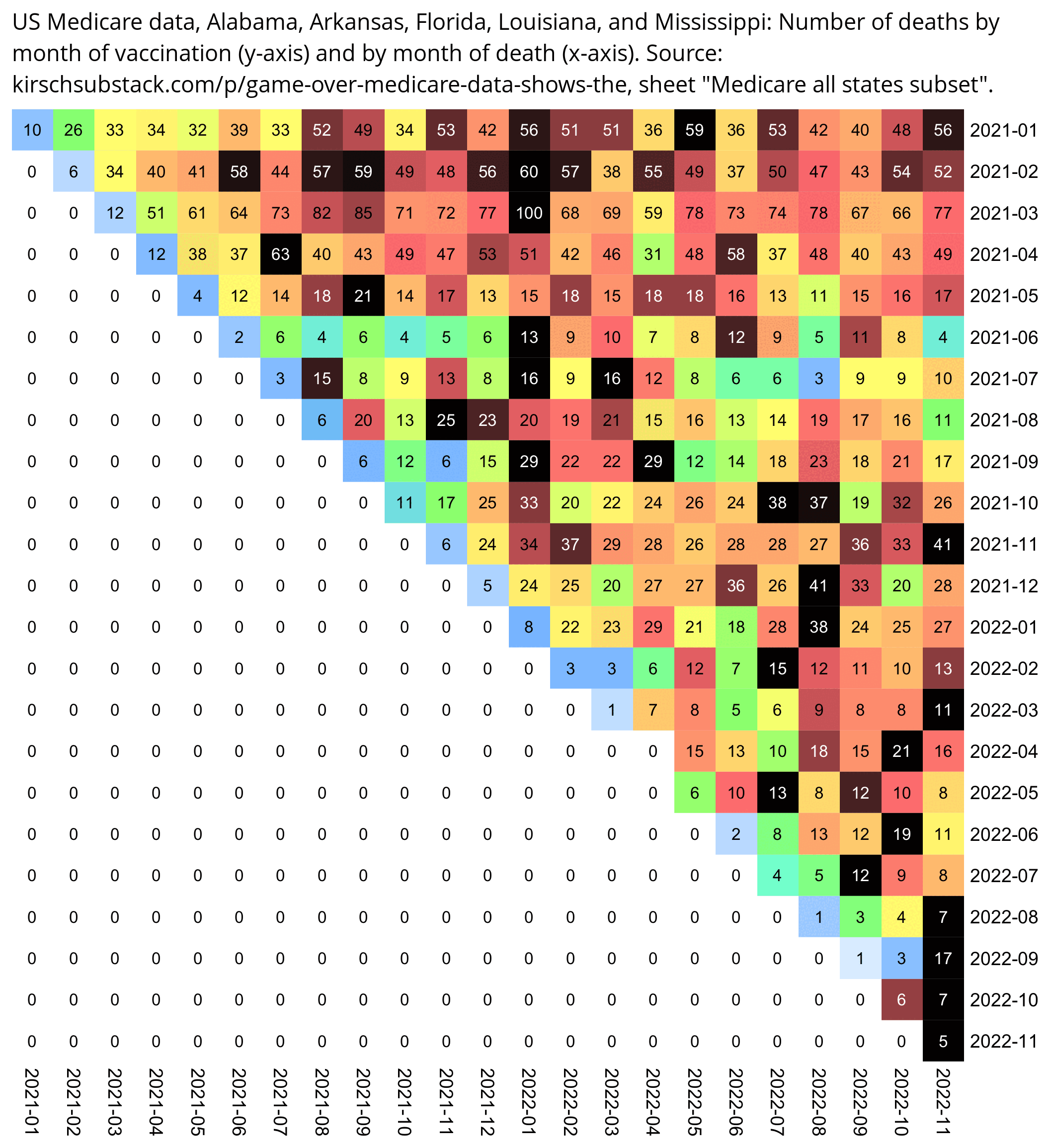
med=read.csv( " https:// sars2. net/ f/ kirsch_ medicare_ all_ states_ subset. csv") med[, 2] =as. Date( med[, 2]) med[, 3] =as. Date( med[, 3]) med=med[ med[, 2] > =" 2021- 01- 01" & med[, 2] < =" 2022- 11- 30",] med=med[ med[, 3] > =" 2021- 01- 01" & med[, 3] < =" 2022- 11- 30",] med=med[ med[, 1]% in% c( " AL", " AR", " FL", " LA", " MS"),] m=table( sub( "...$ ", " ", med$ date_ of_ vaccination), substr( med$ date_ of_ death, 1, 7)) disp=m m=m/ apply( m, 1, max) pheatmap:: pheatmap( m, filename=" 0. png", display_ numbers=disp, cluster_ rows=F, cluster_ cols=F, legend=F, border_ color=NA, cellwidth=20, cellheight=20, fontsize=9, fontsize_ number=8, na_ col=" white", number_ color=ifelse( m>. 85, " white", " black"), breaks=seq( 0, 1,, 256), colorRampPalette( colorspace:: hex( colorspace:: HSV( c( 210, 210, 210, 160, 110, 60, 30, 0, 0, 0), c( 0,. 25, rep(. 5, 8)), c( rep( 1, 8),. 5, 0))))( 256)) system( " convert 0. png -trim -bordercolor white -gravity northwest -splice x16 -size `identify -format %w 0. png` x -pointsize 45 caption: ' US Medicare data, Alabama, Arkansas, Florida, Louisiana, and Mississippi: Number of deaths by month of vaccination (y- axis) and by month of death (x- axis). Source: kirschsubstack. com/ p/ game- over- medicare- data- shows- the, sheet \" Medicare all states subset\ ". ' +swap -append -trim -border 24 +repage 1. png")
In Guam there was also a spike in COVID deaths and PCR positivity rate in September 2021:
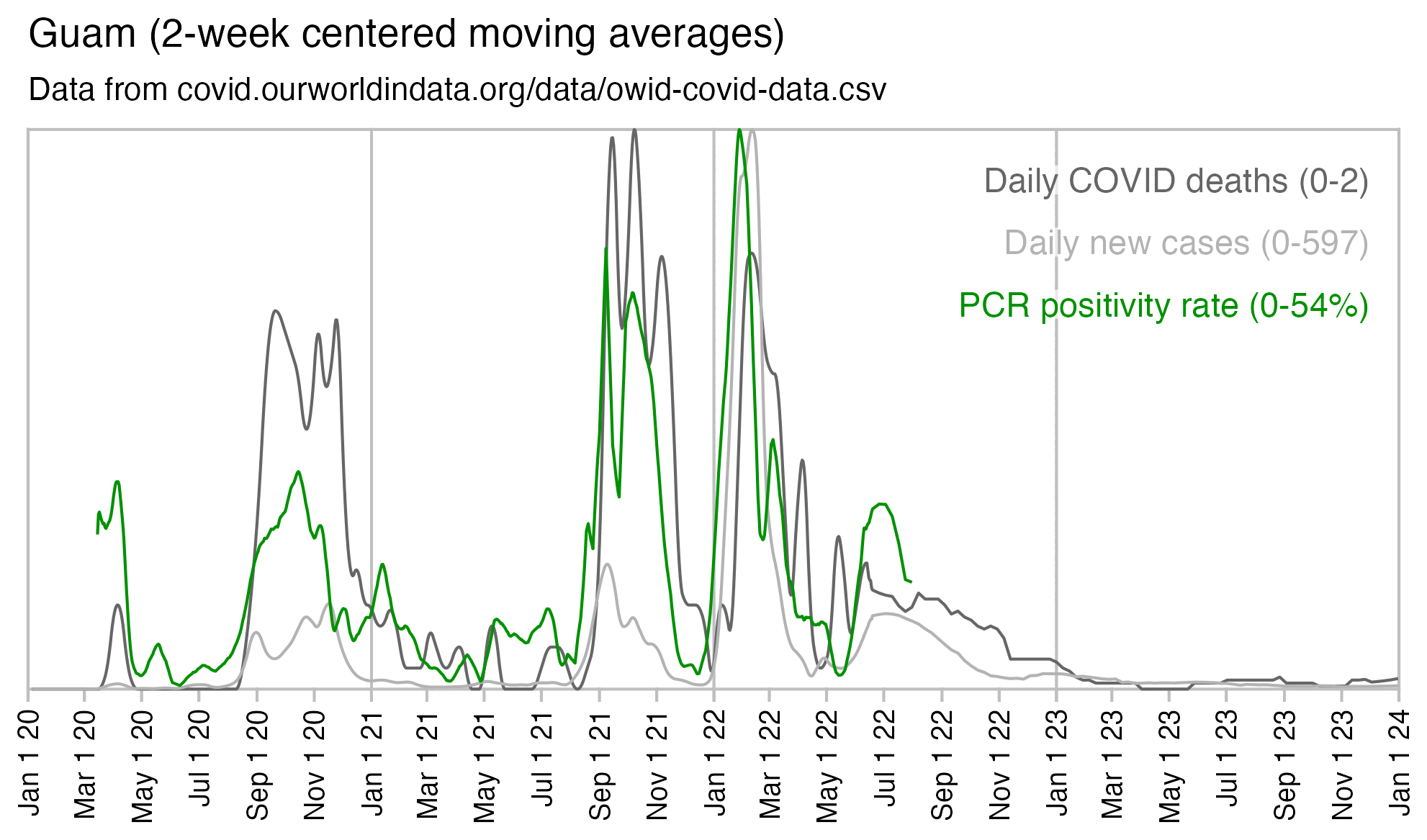
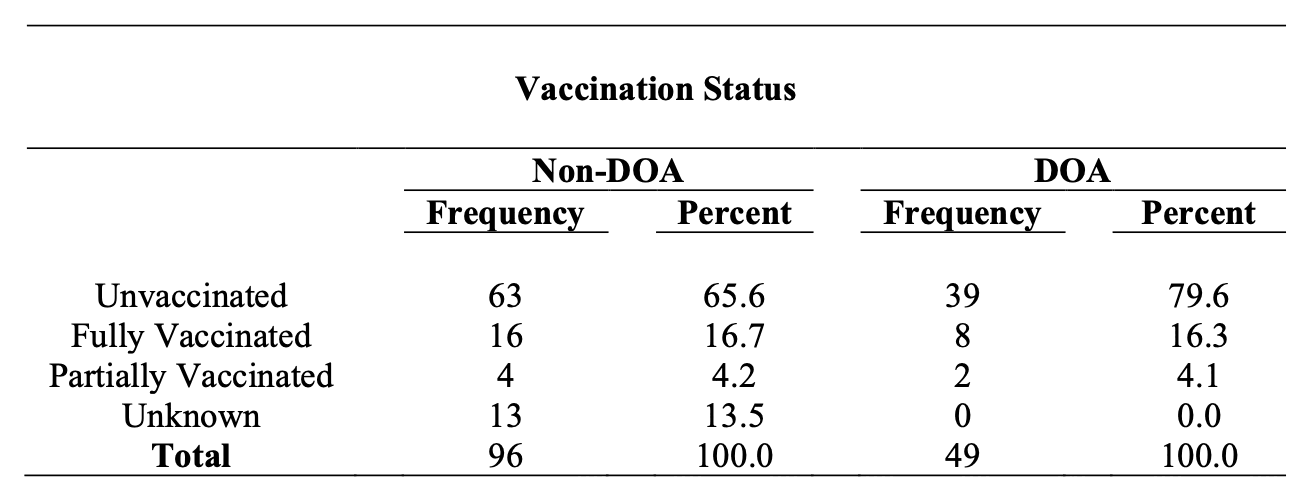
A report about COVID death at Guam said: "Though
overall vaccination coverage in Guam is high with 93.5% of the eligible
population (age ≥5) vaccinated as of
1/22/2022, among individuals who died of COVID-19 in Guam in 2021 with
known vaccination status, over 80% were not fully vaccinated."
[https://
In July to August 2021 there were also news reports that the demand
for vaccines had incresed in southeastern states because of the Delta
wave. For example an article about Louisiana published in early August
2021 said: [https://
But when Madeline LeBlanc relented and got her first vaccine dose this week, she was motivated by something entirely different: fear.
After seeing news reports about the Delta variant raging across the state, Ms. LeBlanc, 24, had come to see that without a vaccine, she risked not just her own life but those of others around her. "I don't want to be the one inhibiting someone else's health," said Ms. LeBlanc, who lives in Baton Rouge.
Demand for the shots has nearly quadrupled in recent weeks in Louisiana, a promising glimmer that the deadly reality of the virus might be breaking through a logjam of misunderstanding and misinformation.
The new push for vaccinations has been driven by an explosion in coronavirus cases.
When I tried comparing the daily number of COVID deaths in 2021 to daily new vaccine doses given, I got a negative correlation for most states, and the correlation got even lower when I shifted the dates of death 10 days into the past. However when I compared daily COVID deaths to PCR positivity rate instead, I got a positive correlation for all states, and the correlation increased even further when I shifted the dates of death by 10 days:
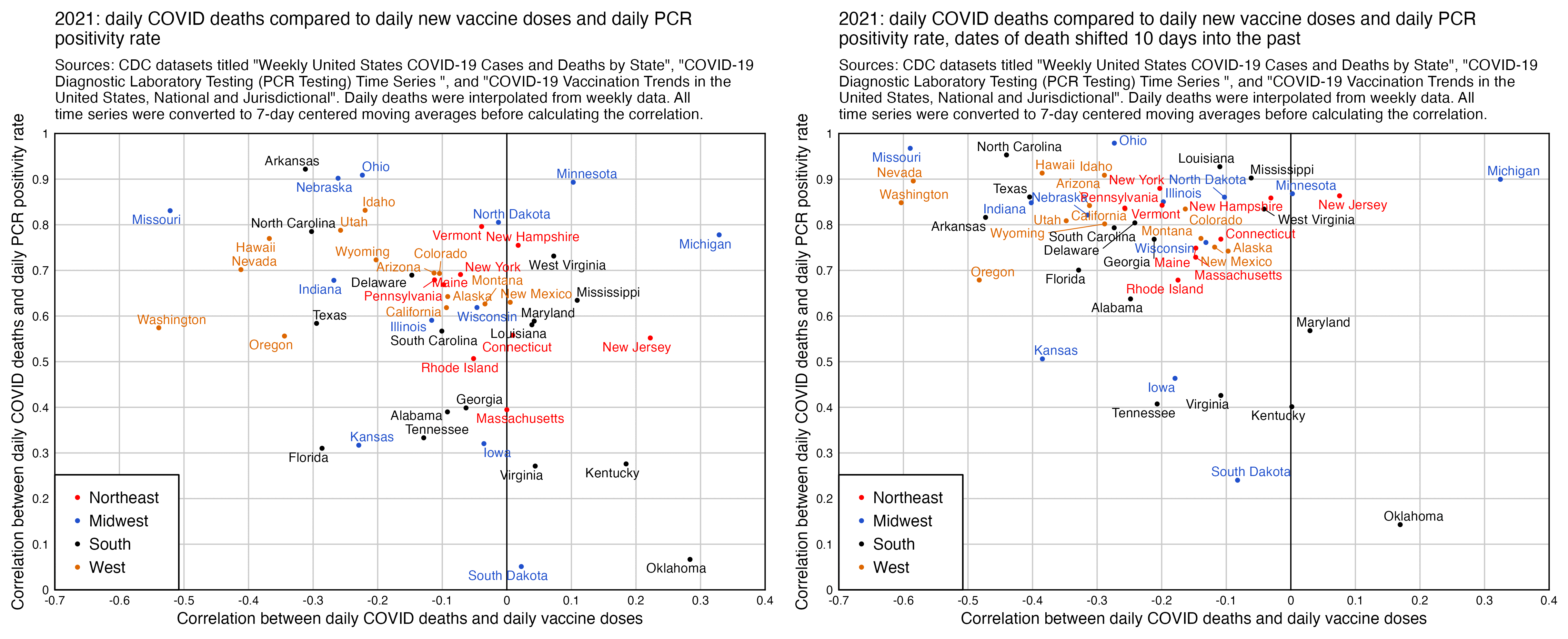
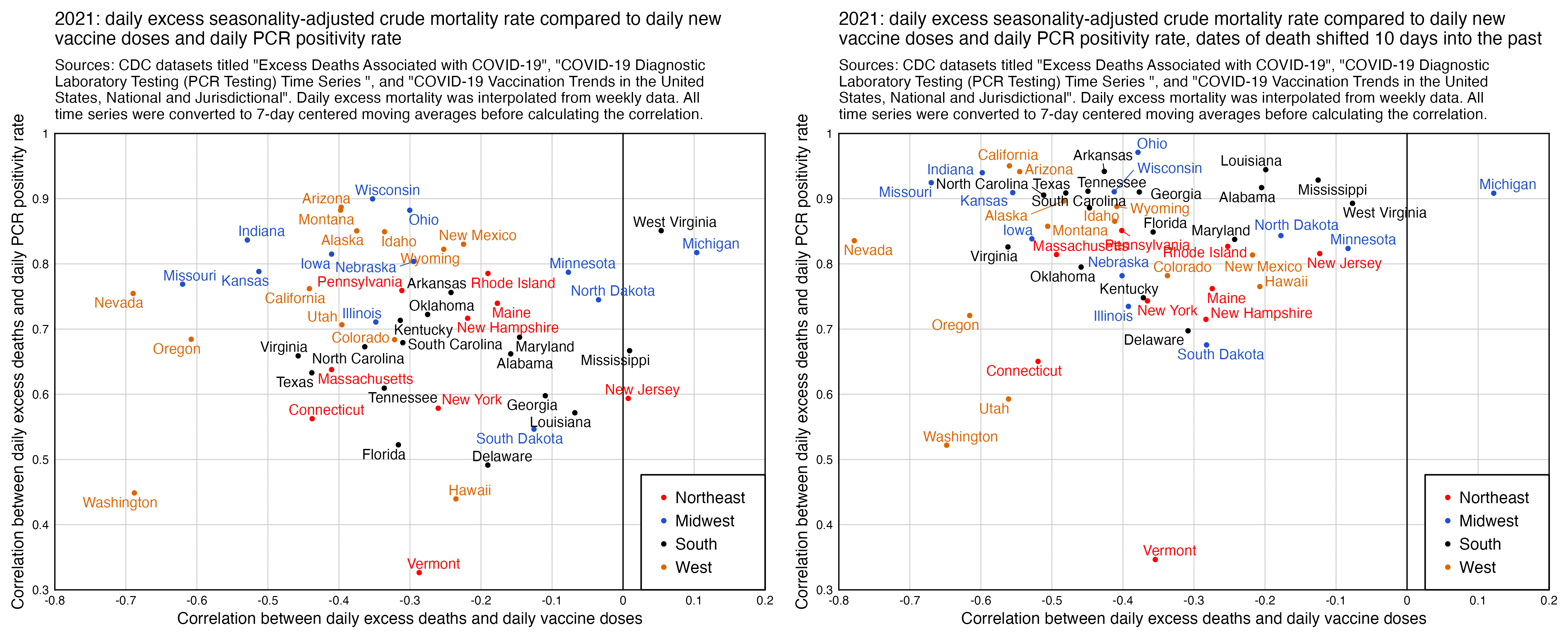
And I got similar results when I looked at excess all-cause deaths and not COVID deaths:
library(ggplot2) download. file( " https:// data. cdc. gov/ api/ views/ rh2h- 3yt2/ rows. csv? accessType=DOWNLOAD", " statesvax. csv") download. file( " https:// data. cdc. gov/ api/ views/ pwn4- m3yp/ rows. csv? accessType=DOWNLOAD", " statescases. csv") download. file( " https:// healthdata. gov/ api/ views/ j8mb- icvb/ rows. csv", " statespcr. csv") vax=read. csv( " statesvax. csv")| > subset( date_ type==" Report") vax[, 1] =as. Date( vax[, 1], "% m/% d/% Y") vax=vax[, c( " Date", " Location", " Administered_ Daily")] colnames( vax) =c( " date", " state", " vax") pcr=read. csv( " statespcr. csv") pos=pcr[ pcr$ overall_ outcome==" Positive", c( 6, 1, 7)] neg=pcr[ pcr$ overall_ outcome==" Negative", c( 6, 1, 7)] pcr=merge( pos, neg, by=c( 1, 2)) pcr=data. frame( as. Date( pcr[, 1], "% Y/% m/% d"), pcr[, 2], pcr=pcr[, 3]/( pcr[, 3]+ pcr[, 4])* 100) cov=read. csv( " statescases. csv")| > subset( state% in% state. abb) cov=data. frame( date=as. Date( cov$ start_ date, "% m/% d/% Y")- 3, state=cov$ state, dead=cov$ new_ deaths)| > subset( grepl( 2021, date)) cov=do. call( rbind, lapply( split( cov, cov$ state),\( x){ x=rbind( x, data. frame( date=as. Date( setdiff( seq( min( x$ date), max( x$ date), 1), x$ date), " 1970- 1- 1"), state=x$ state[ 1], dead=NA)); x=x[ order( x$ date),]; x$ dead=zoo:: na. approx( x$ dead, na. rm=F)/ 7; x})) # cov[, me=merge(1] =cov[, 1]- 10 vax, pcr, by=1: 2)| > merge( cov, by=1: 2) ma=\( x, b=1, f=b) rowMeans( embed( c( rep( NA, b), x, rep( NA, f)), f+ b+ 1), na. rm=T) xy=t( split( me, me$ state)| > sapply(\(