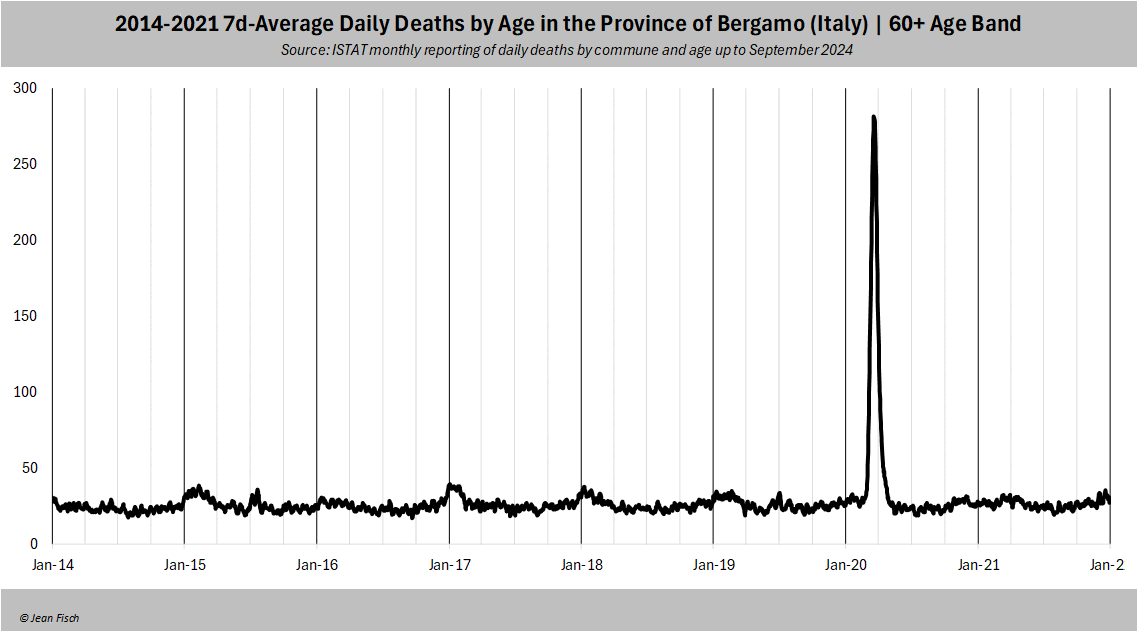
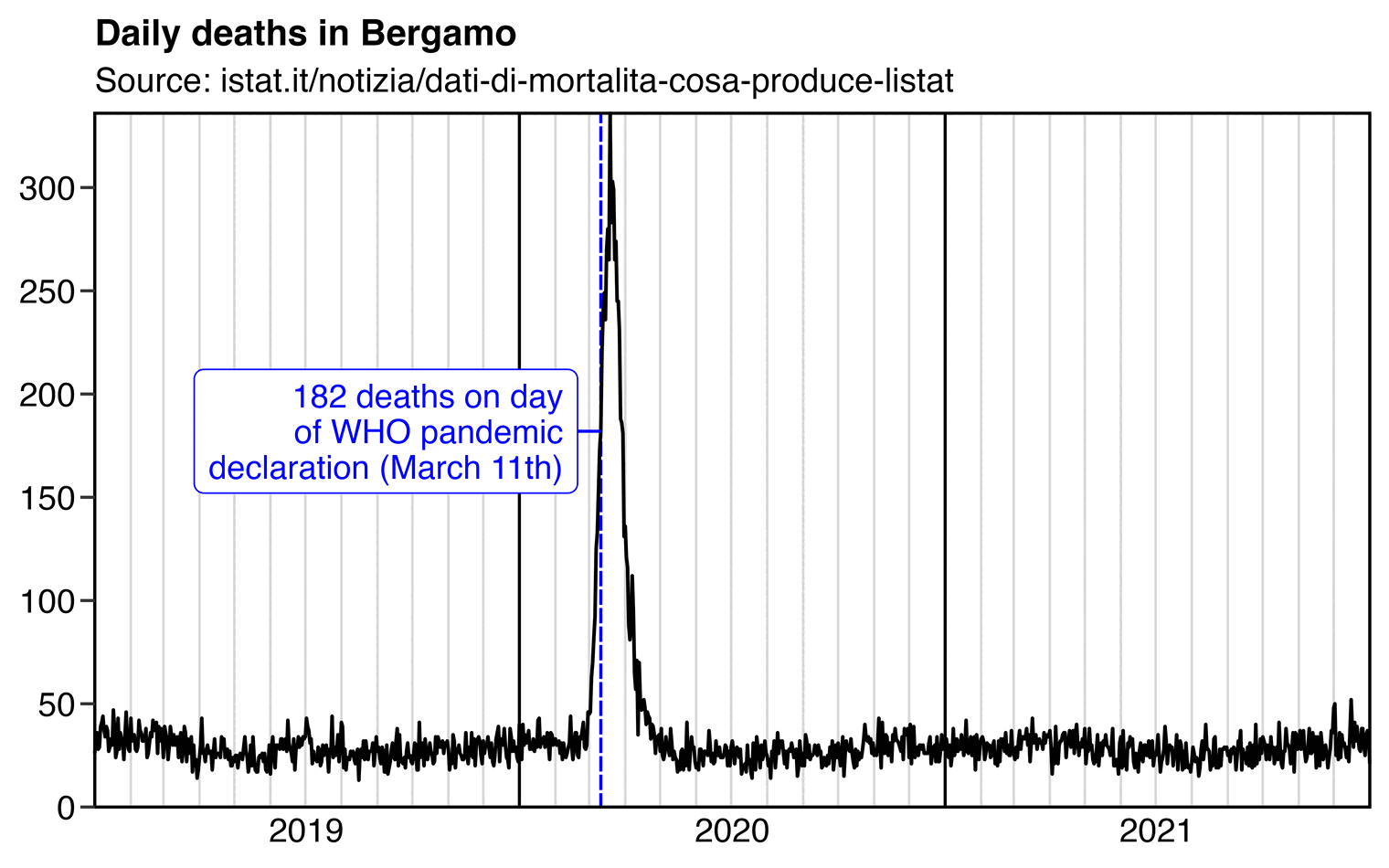
An old myth got revived in GER around "Bergamo
mass deaths must be a fake because there was no mass death deficit
afterwards"
What gets forgotten is that such a deficit is a) small (4% of the
excess with covid) b) mostly taken care off in mortality trend based
expected deaths
First of all: why is the displacement small? Here is the simplest way
to explain it
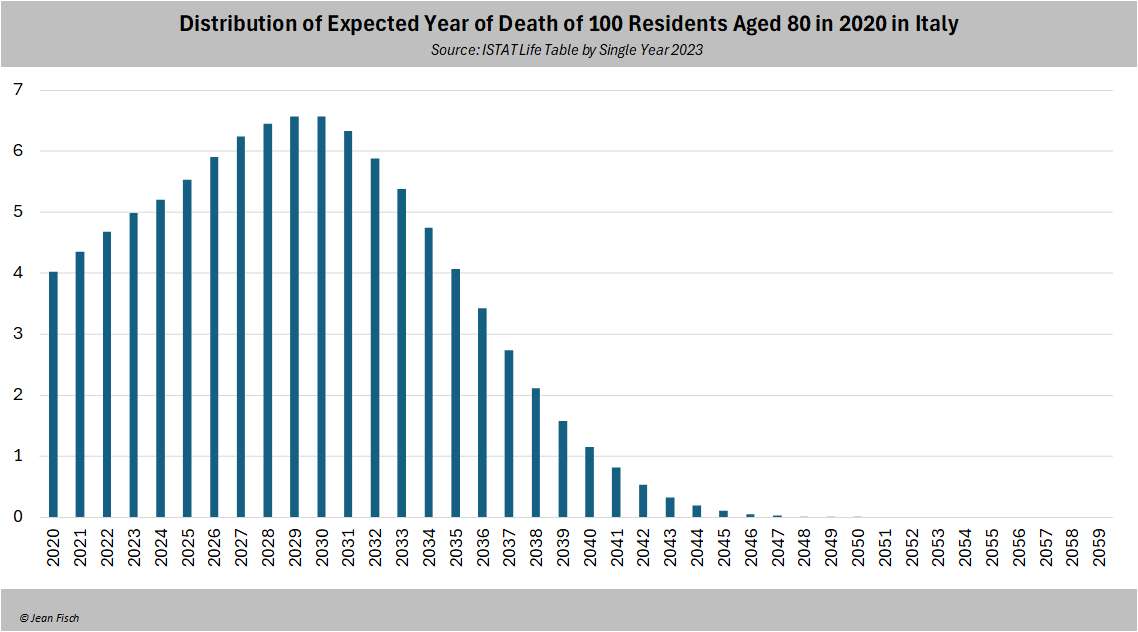
The average age of a covid death in Spring 2020 in Bergamo was 80
If you look at the annual probability of dying in Italy of an 80 yo,
<5% with die aged 81 or 82 (ie in 2021 or 2022 for Bergamo)
If you get now confused because you get 83 years after googling "Life Expectancy Italy", that's because the 83
years is the expectancy at BIRTH
Once you reach 80, your life expectancy is 10 years and that explains
why the stats say that only <5% of 80s old die annually at first
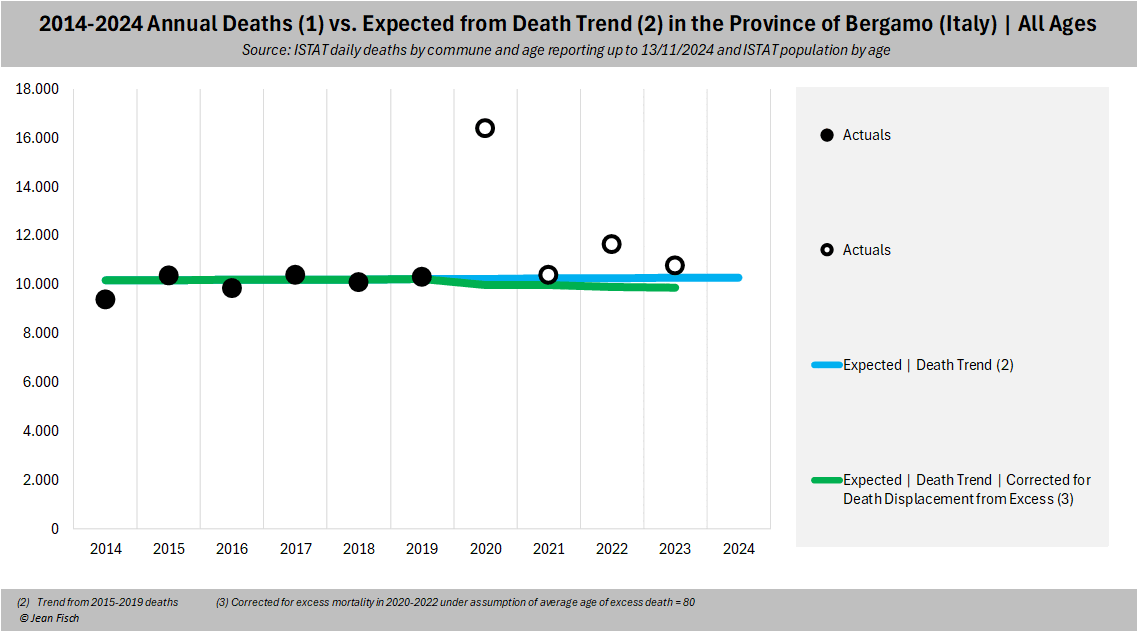
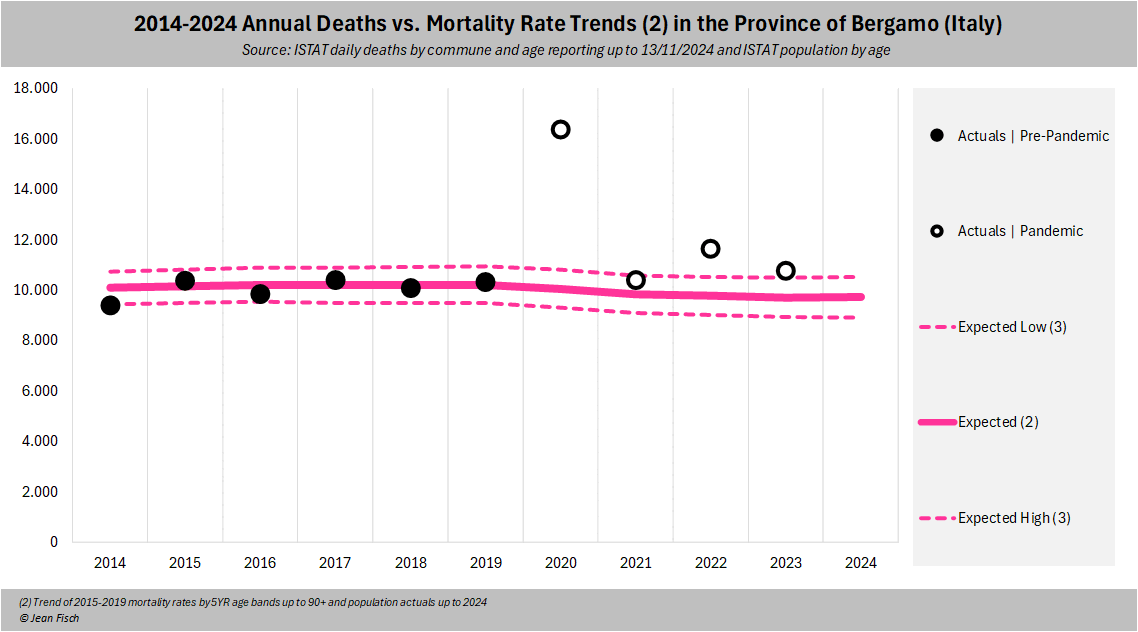
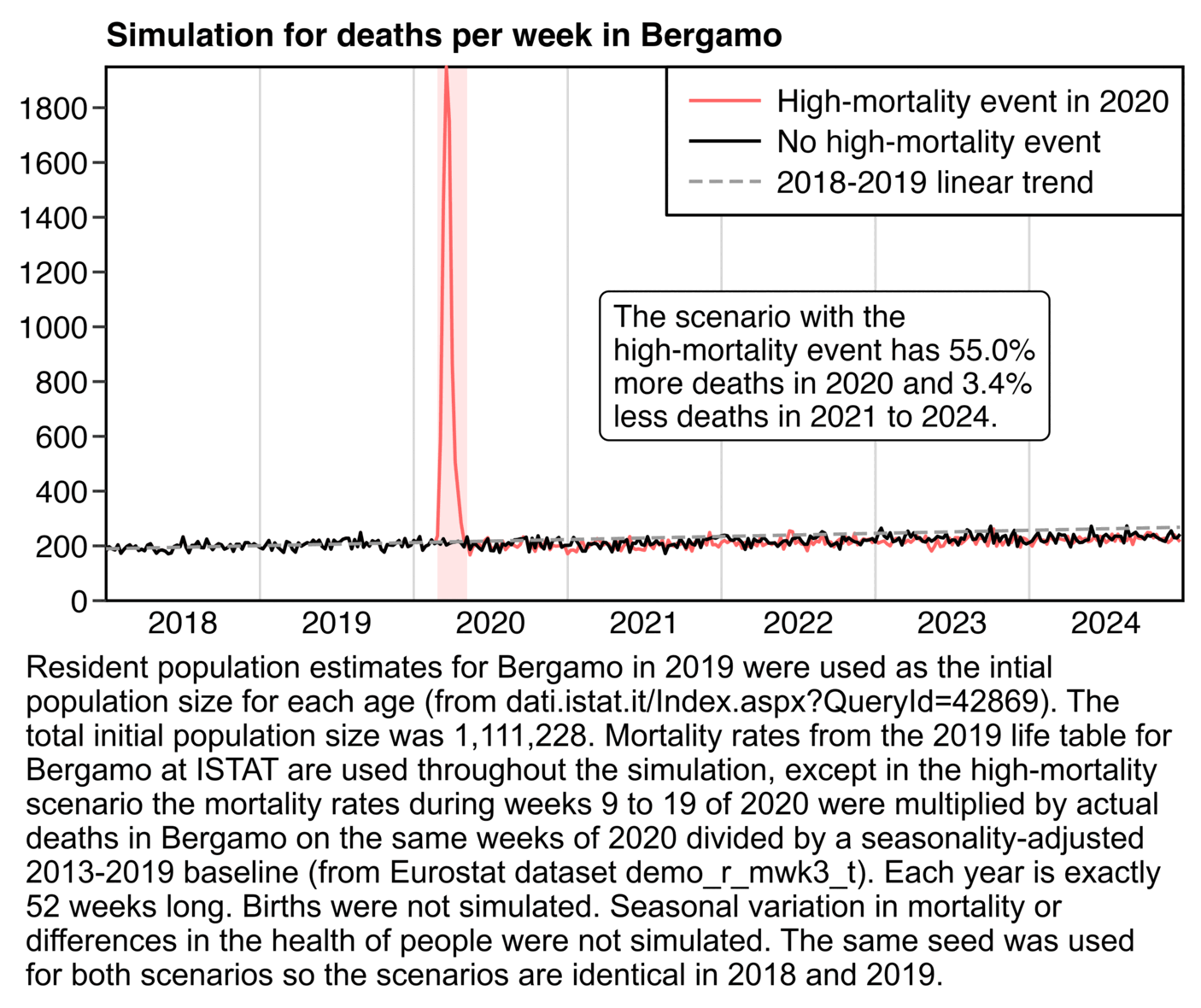
Let's go back to Bergamo: The huge spike of deaths led to 6,000
excess deaths on a usual basis of 10,000 (rounded)
So these 6,000, aged 80 on average, will be "missing" in the death statistics of the following
years and expectations need to be corrected accordingly
How much does make out annually? It means approx. 250-300 fewer
deaths to be expected in 2021-2023 (4-5% of 6,000)
So you see, despite a 60% excess in 2020, stats tell you that there
are ONLY 2.5-3% fewer deaths (ie a tiny %) to be expected less annually
in 2021-2023
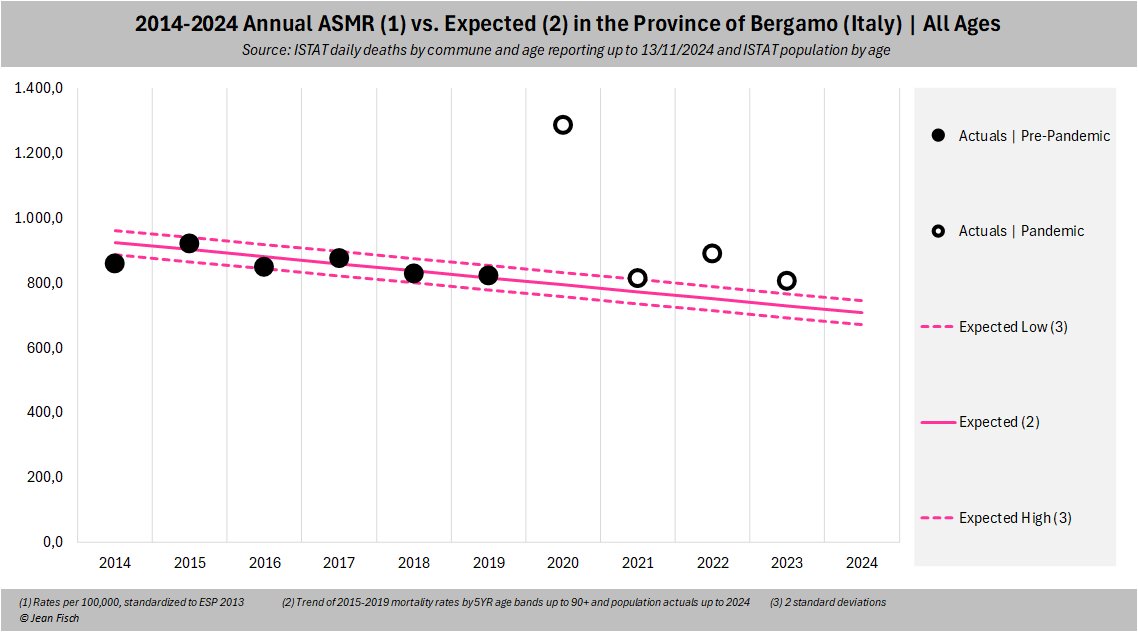
But there is more: Most advanced stats and health institutions
monitor excess mortality against trends from MORTALITY RATES, not
deaths
The reason is that the rate of improvement of mortality rates has
been more or less linear over the past years (so a good indicator)
What one then does is to multiply these expected mortality rates
(ideally by age band) by population actuals to get expected deaths
This also has the advantage to automatically incorporate the changes
in age pyramid seen lately in western democracies, especially in old age
bands
But this has the additional advantage that this method for expected
deaths immediately also incorporates a massive excess in one year
Why? Because (here for Bergamo) the population will be smaller the
year there after and the expected deaths automatically corrected
accordingly
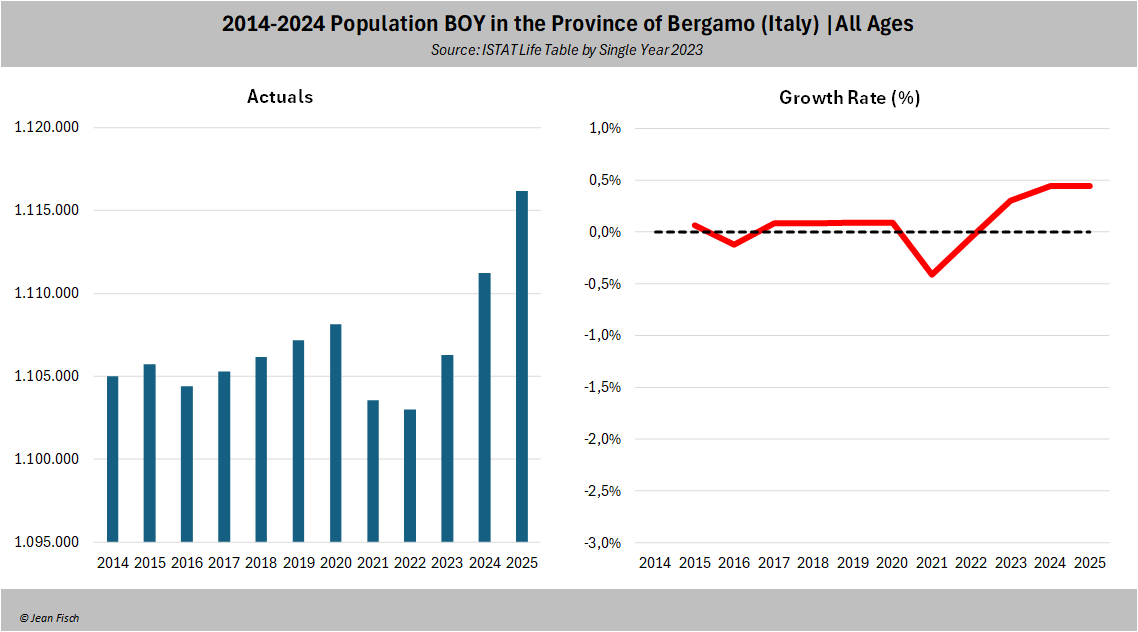
And this is exactly what happens in Bergamo
After an "upwards trend up to 2019",
expected deaths from mortality rates then go down after 2020 due to the
sizeable excess
(also they are roughly the same as the one calculated using corrected
deaths, as they should be)
In summary, there are two "ahas" on death
displacement following excess
TAKEAWAY 1: Views that "Bergamo's huge death peak
is fake because we didn't see a massive deficit in the subsequent
years" are just an expression of a lack of understanding how
mortality works
TAKEAWAY2: In principle, high excess in a year does not require
tweaking the expected deaths thereafter if these were estimated from
mortality trends
I mention this because I see this argument made regularly
FWIW, all my mortality analysis is based on mortality trend
END
I took the 2019 US life table for both sexes combined from the
spreadsheet linked here:
https://www.cdc.gov/nchs/data/nvsr/nvsr70/nvsr70-19.pdf.
I then calculated excess deaths for each age in NYC relative to a
2010-2019 linear trend, but the average life expectancy of the people
who died in excess was about 15 years, even though the average age of
the people who died in excess was about 73. I excluded ages 0 to 15
because they had some years with less than 10 deaths so the number of
deaths was suppressed by CDC WONDER. And even when I excluded all ages
below 50 to reduce the impact of drug deaths, the average life
expectancy remained at about 13 years:
download.file("https://ftp.cdc.gov/pub/Health_Statistics/NCHS/Publications/NVSR/70-19/Table01.xlsx","Table01.xlsx")
t=data.table(readxl::read_excel("Table01.xlsx",skip=2))
t=t[,.(age=as.numeric(sub("\\D.*","",t[[1]])),expectancy=ex)][1:101]
# deaths where county of residence was one of 5 counties of NYC at CDC WONDER
dead=fread("http://sars2.net/f/nycyearlydead.csv")[age>=16]
base=dead[year%in%2010:2019,.(year=2020,base=predict(lm(dead~year),.(year=2020))),age]
me=merge(t,merge(base,dead)[,.(excess=dead-base,age)])
me[,weighted.mean(age,excess)] # 73.04446 (average age of excess deaths)
me[,weighted.mean(expectancy,excess)] # 15.1019 (life expectancy for ages 16 and above)
me[age>=50,weighted.mean(expectancy,excess)] # 12.98951 (life expectancy for ages 50 and above)
However if the mean life expectancy of people who died in excess in
NYC in 2020 was about 15 years, many of the people aren't expected to
have died even 15 years after 2020, so the PFE adjustment should last
much longer than until the end of October 2027.
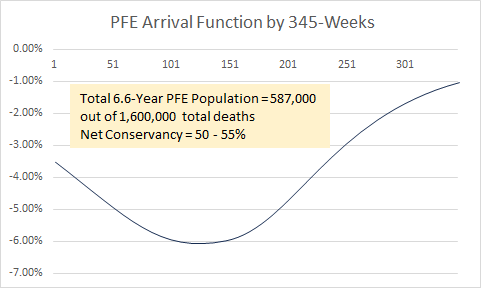
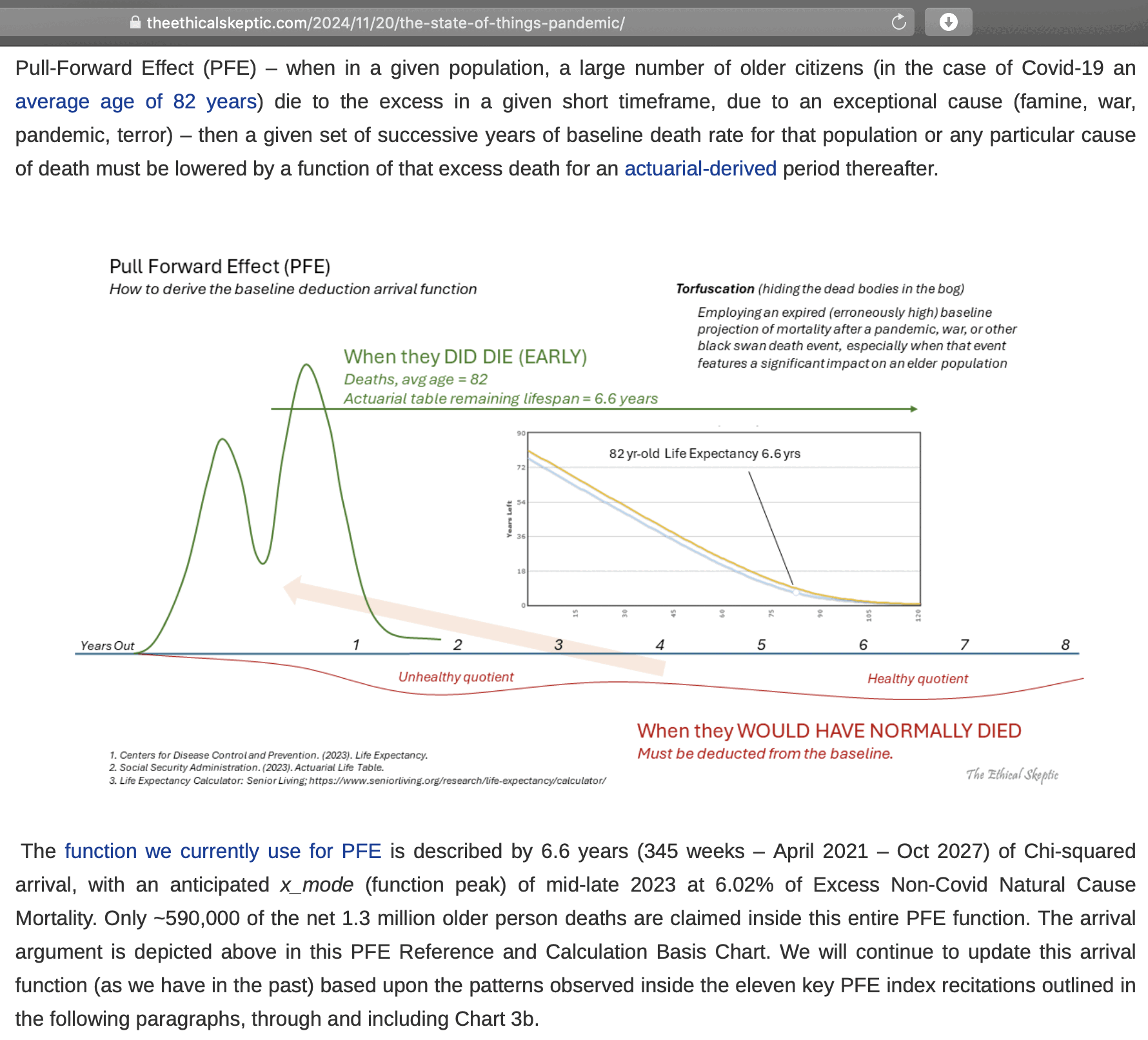
Ethical Skeptic came up with the figure of 6.6 years because he said
the average age of COVID deaths in Florida was 82, and he got a life
expectancy of 6.6 years for age 82 from some unspecified source (even
though in the 2019 US life expectancy table the life expectancy for age
82 is about 8.2 years):
[https://theethicalskeptic.com/2024/11/20/the-state-of-things-pandemic/]
At CDC WONDER the average age of UCD COVID deaths was 73.8 in Florida
and about 73.9 in the whole US. And in the 2019 life table the life
expectancy for age 74 is about 13.1 years, so it's about twice as high
as Ethical Skeptic's figure of 6.6 years. And the average of life
expectancies for each age weighted by the number of COVID deaths for the
age was about 14.5 years:
# 2019 life expectancy table for both sexes combined
download.file("https://ftp.cdc.gov/pub/Health_Statistics/NCHS/Publications/NVSR/70-19/Table01.xlsx","Table01.xlsx")
ex=read_excel("Table01.xlsx",skip=2,n_max=101)$ex
# UCD COVID deaths by single year of age from CDC WONDER (last value is age 100 and above)
coviddead=c(363,116,46,41,39,30,38,32,33,47,40,35,41,56,51,97,88,130,162,210,255,288,367,407,499,530,620,707,819,979,1112,1255,1329,1441,1607,1703,1850,2066,2237,2502,2713,2987,3253,3486,3942,4197,4610,4912,5686,6278,7075,7365,8017,8227,8942,9822,11084,11748,12866,14070,15174,16061,17259,18347,19229,20037,20443,20874,22012,22623,23586,24446,25783,27417,27760,26024,26237,27531,28188,27690,27437,27093,27200,27223,26753,26849,26190,25121,24827,24104,22756,21336,19309,17787,15069,12656,10416,8337,6321,4626,8773)
weighted.mean(ex,coviddead) # 14.50457
The following code shows the average life expectancy by month for
deaths with UCD COVID. I now calculated the life expectancy separately
for males and females even though it didn't make much difference. CDC
WONDER suppresses the number of deaths on rows with less than 10 deaths,
so I got the number of COVID deaths from the fixed-width files for the
NVSS data instead:
stat.html#Download_fixed_width_and_CSV_files_for_the_NVSS_data_used_at_CDC_WONDER.
The life expectancy was unsurprisingly much higher in 2021 than 2020
(which is because the percentage of COVID deaths in 2021 relative to
2020 is much higher in working-age people than in elderly people, which
might be because in 2021 working-age people were less likely to be
vaccinated than elderly people):
Next I made the simulation below using data from ISTAT and Eurostat:
http://dati.istat.it/Index.aspx?QueryId=42869&lang=en,
https://ec.europa.eu/eurostat/api/dissemination/sdmx/2.1/data/demo_r_mwk3_t?format=TSV.
At first I also tried simulating different people having different
levels of health, but I didn't find an accurate way to do it so I left
it out of the simulation. When I simply assigned a fixed health
multiplier to each person, the people with poor health tended to die at
the start of the simulation which artificially elevated deaths at the
start of the simulation compared to the end of the simulation. So I
should've also modeled the health status of people getting worse over
time so that over time new people would've gradually entered the verge
of death, but it seemed too difficult to model realistically. But
anyway, here in the red scenario where I simulated a spike in excess
deaths in spring 2020, I got only about 3.4% less deaths in 2021-2024
than in the black scenario without the spike:
library(data.table);library(ggplot2)
euro=fread("https://ec.europa.eu/eurostat/api/dissemination/sdmx/2.1/data/demo_r_mwk3_t?format=TSV")
x=unlist(euro[euro[[1]]%like%"ITC46"])[-1];x=x[x!=":"]
d=data.table(year=as.integer(substr(names(x),1,4)),week=as.integer(substr(names(x),7,8)))[,x:=.I]
d$dead=as.integer(sub(" .*","",x))
d$trend=d[year%in%2013:2019,predict(lm(dead~x),d)]
d=merge(d,d[year%in%2013:2019,.(weekly=mean(dead-trend)),week])
mult=d[year==2020&week%in%9:19,dead/(trend+weekly)]
pop=c(7406,7625,7880,7909,8570,8867,9439,9725,9850,10350,10545,10991,11427,11617,11950,11864,11816,11905,11706,11809,11864,11769,11942,12225,11878,12078,12004,11527,11715,11477,11525,11993,11984,12231,12064,12631,12406,12205,12752,13256,13417,13627,14005,14351,14612,15773,16026,16577,17824,18126,18084,18163,17907,18161,18285,18240,18270,18805,18653,18690,17266,16377,15528,15325,14804,14145,13294,13184,12725,12372,12000,11680,11546,12114,11851,11748,10684,10850,8014,8288,7876,7855,7494,7977,7060,6379,5353,4372,4140,3445,2908,2471,2016,1701,1185,908,660,456,294,229,281)
life=fread("http://sars2.net/f/bergamolifetable.csv")
cmr=life[,sum(deaths)/(sum(deaths)+sum(survivors)),.(age=pmin(age,100))]$V1/52
simweeks=52*7
weekmult=rep(1,simweeks);weekmult[113:123]=mult
people=data.table(age=rep(0:100,pop))[,age:=age+runif(.N)]
people2=copy(people)
sim=data.table(week=1:simweeks,dead=0,dead2=0)
set.seed(0)
for(i in 1:simweeks){
died=people[,rbinom(.N,1,pmin(1,cmr[age+1]*weekmult[i]))]
people=people[died!=1][,age:=pmin(100,age+1/52)]
sim$dead[i]=sum(died)
}
set.seed(0)
for(i in 1:simweeks){
died=people2[,rbinom(.N,1,pmin(1,cmr[age+1]))]
people2=people2[died!=1][,age:=pmin(100,age+1/52)]
sim$dead2[i]=sum(died)
}
sim$base=sim[week<105,predict(lm(dead~week),sim)]
lab=c("High-mortality event in 2020","No high-mortality event","2018-2019 linear trend")
p=sim[,.(x=week,y=unlist(.SD[,-1]),z=factor(rep(lab,each=.N),lab))]
sum=sim[week%in%105:156,colSums(.SD)]
sum2=sim[week>156,colSums(.SD)]
note=stringr::str_wrap(sprintf("The scenario with the high-mortality event has %.1f%% more deaths in 2020 and %.1f%% less deaths in 2021 to 2024.",(sum[2]/sum[3]-1)*100,(sum2[3]/sum2[2]-1)*100),32)
xstart=1;xend=simweeks+1;xbreak=seq(xstart,xend,26);xlab=c(rbind("",2018:2024),"")
ybreak=pretty(c(0,p$y),8);ystart=0;yend=max(p$y)
ggplot(p,aes(x,y))+
geom_rect(xmin=113,xmax=123,ymin=0,ymax=yend,fill="#ffe5e5")+
geom_vline(xintercept=seq(xstart,xend,52),linewidth=.25,color="gray85",lineend="square")+
geom_hline(yintercept=c(ystart,yend),linewidth=.3,lineend="square")+
geom_vline(xintercept=c(xstart,xend),linewidth=.3,lineend="square")+
geom_line(aes(color=z,linetype=z),linewidth=.35)+
labs(title="Simulation for deaths per week in Bergamo",x=NULL,y=NULL)+
annotate(geom="label",x=.46*xend,y=yend*.44,label=note,hjust=0,label.r=unit(2,"pt"),label.padding=unit(3,"pt"),label.size=.2,size=2.4,lineheight=.9)+
scale_x_continuous(limits=c(xstart,xend),breaks=xbreak,labels=xlab)+
scale_y_continuous(limits=c(ystart,yend),breaks=ybreak)+
scale_color_manual(values=c("#ff6666","black","gray60"))+
scale_linetype_manual(values=c("solid","solid","42"))+
coord_cartesian(clip="off",expand=F)+
theme(axis.text=element_text(size=7,color="black"),
axis.text.y=element_text(margin=margin(,1)),
axis.ticks=element_line(linewidth=.3),
axis.ticks.length=unit(3,"pt"),
axis.ticks.length.x=unit(0,"pt"),
legend.direction="vertical",
legend.justification=c(1,1),
legend.key=element_blank(),
legend.key.height=unit(9,"pt"),
legend.key.width=unit(20,"pt"),
legend.background=element_rect(color="black",linewidth=.3),
legend.margin=margin(3,3,3,3),
legend.position=c(1,1),
legend.spacing.x=unit(1.5,"pt"),
legend.spacing.y=unit(0,"pt"),
legend.text=element_text(size=7),
legend.title=element_blank(),
panel.background=element_blank(),
plot.margin=margin(4,4,2,4),
plot.title=element_text(size=7.3,face="bold",margin=margin(1,,3)))
ggsave("1.png",width=3.7,height=2,dpi=380*4)
sub=paste0("Resident population estimates for Bergamo in 2019 were used as the intial population size for each age (from dati.istat.it/Index.aspx?QueryId=42869). The total initial population size was 1,111,228. Mortality rates from the 2019 life table for Bergamo at ISTAT are used throughout the simulation, except in the high-mortality scenario the mortality rates during weeks 9 to 19 of 2020 were multiplied by actual deaths in Bergamo on the same weeks of 2020 divided by a seasonality-adjusted 2013-2019 baseline (from Eurostat dataset demo_r_mwk3_t).")
sub=paste0(sub," Each year is exactly 52 weeks long. Births were not simulated. Seasonal variation in mortality or differences in the health of people were not simulated. The same seed was used for both scenarios so the scenarios are identical in 2018 and 2019.")
system(paste0("mar=120;w=`identify -format %w 1.png`;magick 1.png \\( -size $[w-mar*2]x -font Arial -interline-spacing -4 -pointsize 146 caption:'",gsub("'","'\\'",sub),"' -gravity southwest -splice $[mar]x70 \\) -append -resize 25% -colors 256 1.png"))
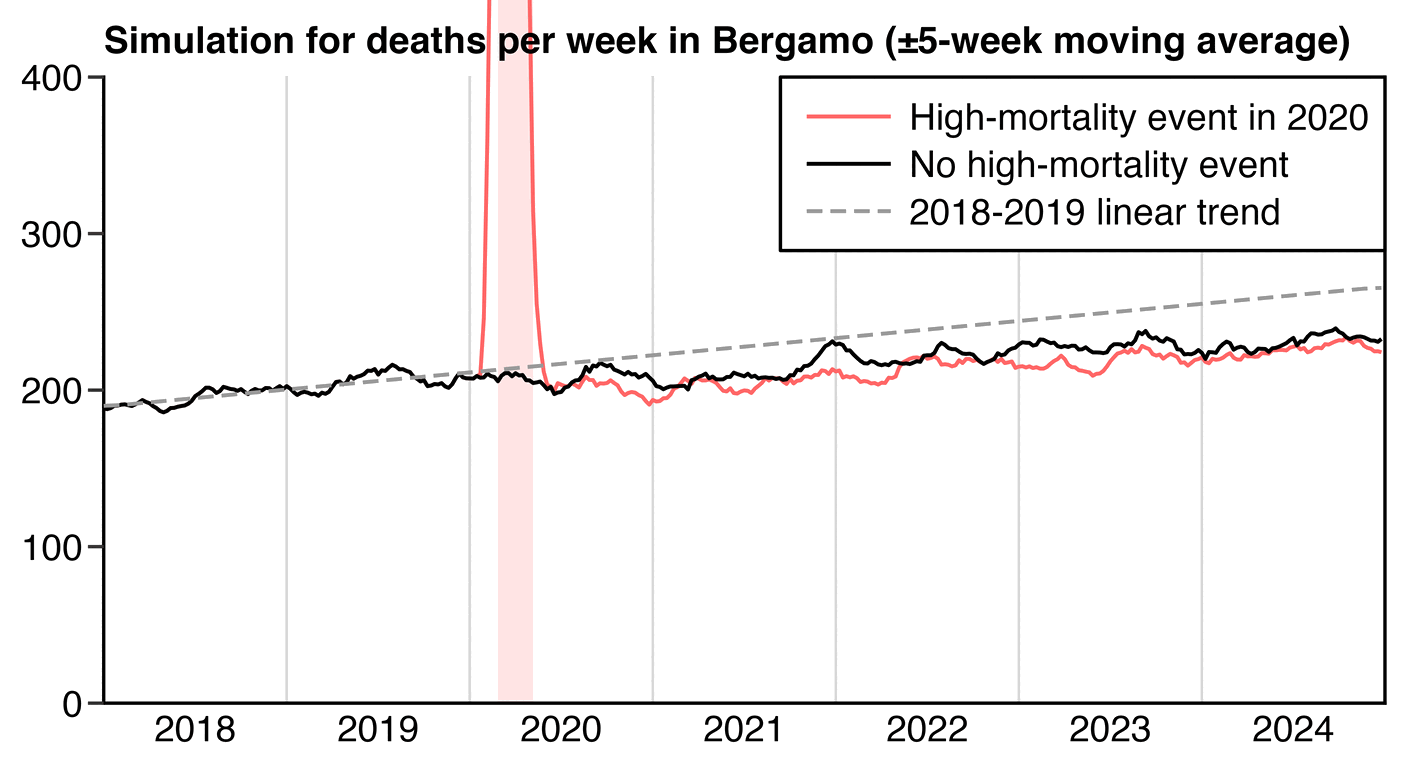
The difference between my simulated scenarios is easier to see in the
next plot where I truncated the y-axis and I plotted the deaths as
moving averages. But in the case of Bergamo the excess deaths were
concentrated to such a brief period of time that the "PFE arrival function" is more like a square wave
than a sine wave, and the depth of the PFE adjustment is more shallow
than in plots by ES (or actually my red line is about 3.4% lower on
average than the black line in 2021-2024, so it's not much lower than
the average depth of Ethical Skeptic's PFE arrival function in
2021-2024, but the depth is still shallower relative to the percentage
of excess deaths which was higher in Bergamo than the United
States):
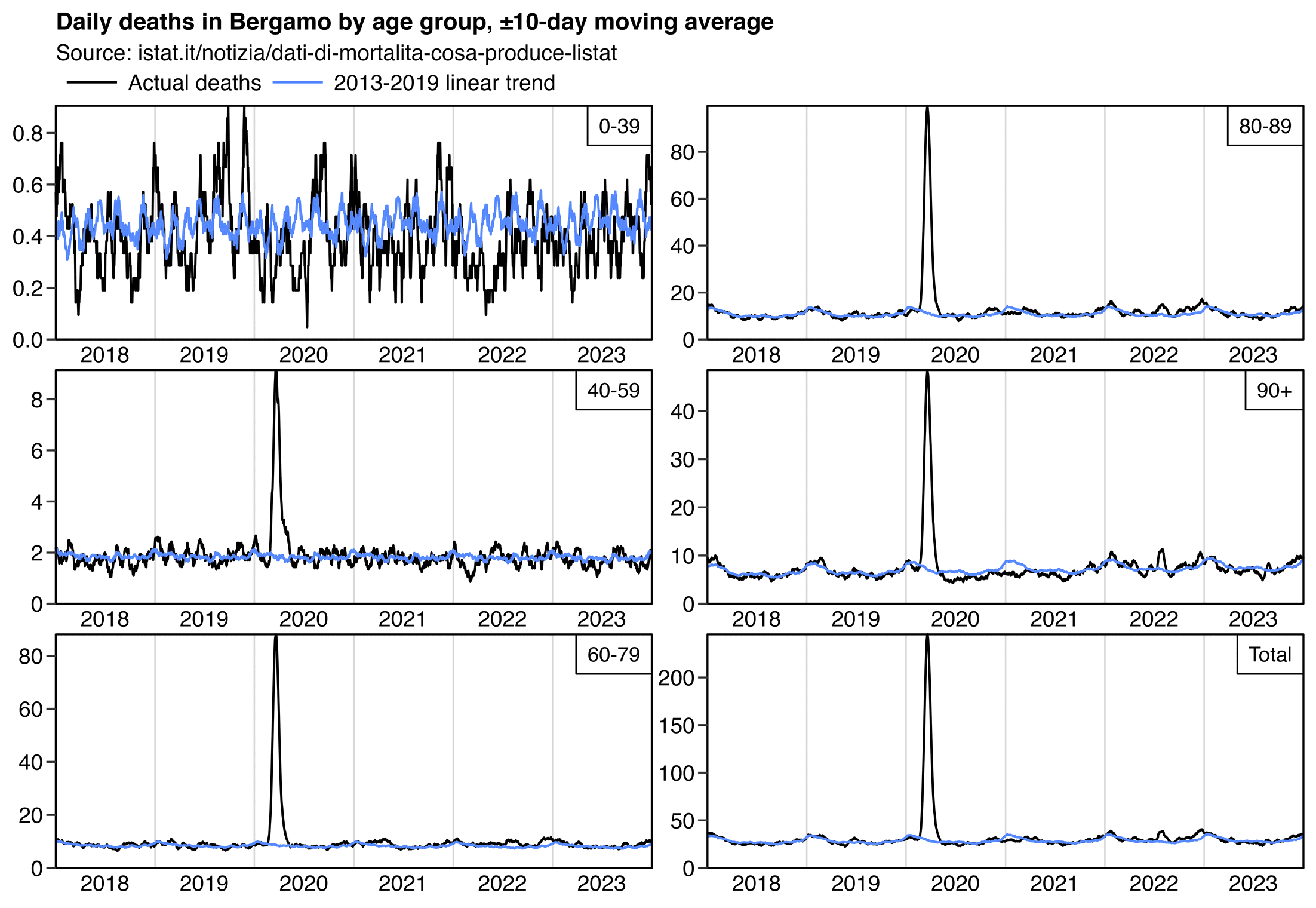
In the plot below which shows real data for deaths in Bergamo, there
seems to be a clear reduction in deaths below the baseline in ages 90+
but not in younger age groups (but ages 90+ also had the biggest
percentage reduction in population size in spring 2020):
Here when I divided the number of excess deaths on weeks 9 to 19 of
2020 with the resident population estimate on January 1st 2020, it was
about 7% in ages 90+ but only about 5% in ages 85-89 and 3% in ages
80-84:
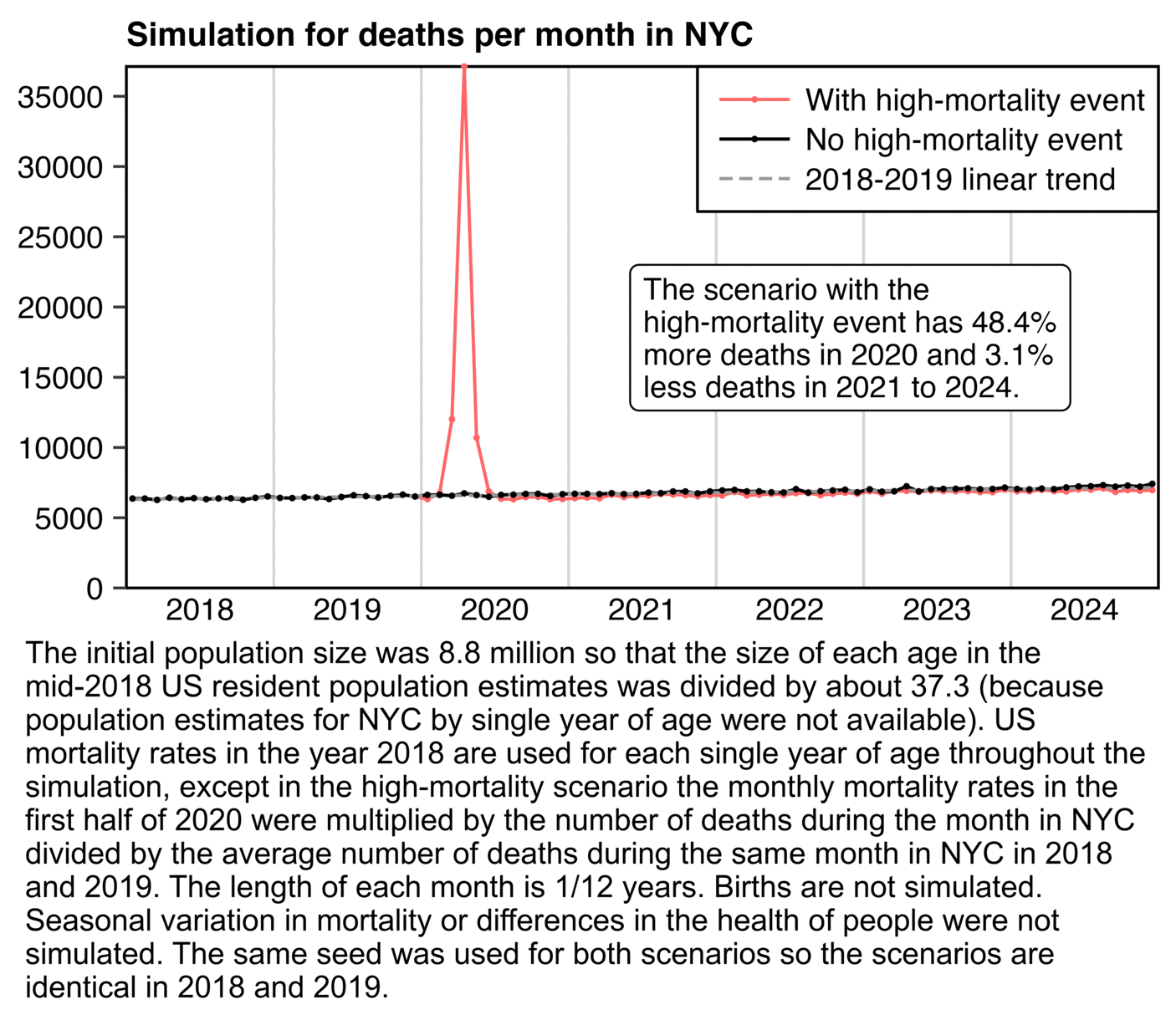
In the next plot I did a similar simulation for NYC as the earlier
simulation for Bergamo. Now the number of deaths in the red scenario
where I simulated the COVID event was only about 3.1% lower in 2021-2024
than in the black scenario without the COVID event. I don't know why the
reduction was so much smaller than in the simulation for Bergamo, even
though the total percentage of excess deaths in the first half of 2020
was only slightly higher in Bergamo than NYC:
library(data.table);library(ggplot2)
simmonths=12*7
monthmult=rep(1,simmonths)
nyc=fread("http://sars2.net/f/nycmonthlydead.csv")
monthmult[25:30]=merge(nyc[year<2020,mean(dead),month],nyc)[year==2020,dead/V1][1:6]
pop=fread("http://sars2.net/f/uspopdead.csv")[year==2018]
cmr=pop[,dead/pop]/12
popfrac=pop[,sum(pop)/8.8e6]
people=data.table(age=pop[,rep(age,pop/popfrac)])[,age:=age+runif(.N)]
people$health=1 # don't model health of people
# sd=1;people[,health:=2^rnorm(.N,log(2)*sd^2/-2,sd)] # include health multipliers in model
sim=data.table(month=1:simmonths,dead=0,dead2=0)
people2=copy(people)
set.seed(0)
for(i in 1:simmonths){
died=people[,rbinom(.N,1,pmin(1,cmr[age+1]*health*monthmult[i]))]
people=people[died!=1][,age:=pmin(100,age+1/12)]
sim$dead[i]=sum(died)
}
set.seed(0)
for(i in 1:simmonths){
died=people2[,rbinom(.N,1,pmin(1,cmr[age+1]*health))]
people2=people2[died!=1][,age:=pmin(100,age+1/12)]
sim$dead2[i]=sum(died)
}
sim$base=sim[month<25,predict(lm(dead~month),sim)]
lab=c("With high-mortality event","No high-mortality event","2018-2019 linear trend")
p=sim[,.(x=month,y=unlist(.SD[,-1]),z=factor(rep(lab,each=.N),lab))]
sum=sim[month%in%25:36,colSums(.SD)]
sum2=sim[month>36,colSums(.SD)]
note=stringr::str_wrap(sprintf("The scenario with the high-mortality event has %.1f%% more deaths in 2020 and %.1f%% less deaths in 2021 to 2024.",(sum[2]/sum[3]-1)*100,(sum2[3]/sum2[2]-1)*100),32)
xstart=1;xend=simmonths+1;xbreak=seq(xstart,xend,6);xlab=c(rbind("",2018:2024),"")
ybreak=pretty(c(0,p$y),8);ystart=0;yend=max(p$y)+.02
ggplot(p,aes(x+.5,y))+
geom_vline(xintercept=seq(xstart,xend,12),linewidth=.3,color="gray83",lineend="square")+
geom_hline(yintercept=c(ystart,yend),linewidth=.3,lineend="square")+
geom_vline(xintercept=c(xstart,xend),linewidth=.3,lineend="square")+
geom_line(aes(color=z,linetype=z),linewidth=.35)+
geom_point(aes(color=z,alpha=z),stroke=0,size=.7)+
labs(title="Simulation for deaths per month in NYC",x=NULL,y=NULL)+
annotate(geom="label",x=42,y=yend*.48,label=note,hjust=0,label.r=unit(2,"pt"),label.padding=unit(3,"pt"),label.size=.2,size=2.4,lineheight=.9)+
scale_x_continuous(limits=c(xstart,xend),breaks=xbreak,labels=xlab)+
scale_y_continuous(limits=c(ystart,yend),breaks=ybreak)+
scale_color_manual(values=c("#ff6666","black","gray60"))+
scale_alpha_manual(values=c(1,1,0))+
scale_linetype_manual(values=c("solid","solid","42"))+
coord_cartesian(clip="off",expand=F)+
theme(axis.text=element_text(size=7,color="black"),
axis.ticks=element_line(linewidth=.3),
axis.ticks.length=unit(3,"pt"),
axis.ticks.length.x=unit(0,"pt"),
legend.direction="vertical",
legend.justification=c(1,1),
legend.key=element_blank(),
legend.key.height=unit(9,"pt"),
legend.key.width=unit(20,"pt"),
legend.background=element_rect(color="black",linewidth=.3),
legend.margin=margin(3,3,3,3),
legend.position=c(1,1),
legend.spacing.x=unit(1.5,"pt"),
legend.spacing.y=unit(0,"pt"),
legend.text=element_text(size=7),
legend.title=element_blank(),
panel.background=element_blank(),
plot.margin=margin(4,4,2,4),
plot.title=element_text(size=7.5,face="bold",margin=margin(1,,3)))
ggsave("1.png",width=3.7,height=2,dpi=380*4)
sub=paste0("The initial population size was 8.8 million so that the size of each age in the mid-2018 US resident population estimates was divided by about 37.3 (because population estimates for NYC by single year of age were not available). US mortality rates in the year 2018 are used for each single year of age throughout the simulation, except in the high-mortality scenario the monthly mortality rates in the first half of 2020 were multiplied by the number of deaths during the month in NYC divided by the average number of deaths during the same month in NYC in 2018 and 2019.")
sub=paste0(sub," The length of each month is 1/12 years. Births are not simulated. Seasonal variation in mortality or differences in the health of people were not simulated. The same seed was used for both scenarios so the scenarios are identical in 2018 and 2019.")
system(paste0("mar=120;w=`identify -format %w 1.png`;magick 1.png \\( -size $[w-mar*2]x -font Arial -interline-spacing -4 -pointsize 146 caption:'",gsub("'","'\\'",sub),"' -gravity southwest -splice $[mar]x70 \\) -append -resize 25% -colors 256 1.png"))
In Ethical Skeptic's plots which display weekly excess deaths from
2018 onwards, he fits a linear baseline against deaths from only 2018
and 2019. However his baseline is often too low especially in 2023 and
2024, because the long-term trend in deaths is curved upwards due to the
aging population, so in addition to adjusting his baseline downwards to
account for the PFE, he should also adjust his baseline upwards to
account for the aging population. In my simulation above between the
second half of 2020 and 2024, the difference between the black line and
gray 2018-2019 baseline was about twice as big than the difference
between the black and red lines. But basically Ethical Skeptic should
also adjust his linear baseline so it would be slightly curved upwards
like the black line in my simulation above.
Jean Fisch pointed out to Jessica Hockett that "the average age of a covid death was 80" and "80yo Italians have only an annual probabilitty of 4% of
dying in each of the 3 subsequent years".
[https://x.com/Jean%5f%5fFisch/status/1861413598343663657]
However it might be more accurate to calculate the weighted average of
the probability of dying over the next year where the weight is the
number of COVID deaths for each age. I didn't find deaths in Bergamo by
single year of age. But when I multiplied the likelihood of dying over
the next year from the 2019 US life table with the number of excess
deaths for each age in NYC in 2020, the overall probability of dying
over the next year was about 6.3%:
# 2019 US life table for both sexes combined
download.file("https://ftp.cdc.gov/pub/Health_Statistics/NCHS/Publications/NVSR/70-19/Table01.xlsx","Table01.xlsx")
qx=setDT(readxl::read_excel("Table01.xlsx",skip=2,n_max=101))[,.(age=0:100,ex)]
# yearly deaths from CDC WONDER where the county of occurrence is one of 5 counties of NYC
# ages below 16 are excluded because they had years where the number of deaths was suppressed
dead=fread("http://sars2.net/f/nycyearlydead.csv")[age>=16]
base=dead[year%in%2010:2019,.(year=2020,base=predict(lm(dead~year),.(year=2020))),age]
me=merge(qx,merge(base,dead)[,.(excess=dead-base),age])
me[,weighted.mean(qx,excess)] # 0.06320128 (about 6.3% probability of dying over the next year)
In the next code for Bergamo I used 5-year age groups up to 90+
because I didn't find data for deaths by single year of age. But when I
took a weighted average of 2019 mortality rates where the weight was the
number of excess deaths for each age group on weeks 9 to 19 of 2020, the
resulting likelihood of dying over the next year was about 7.0%:
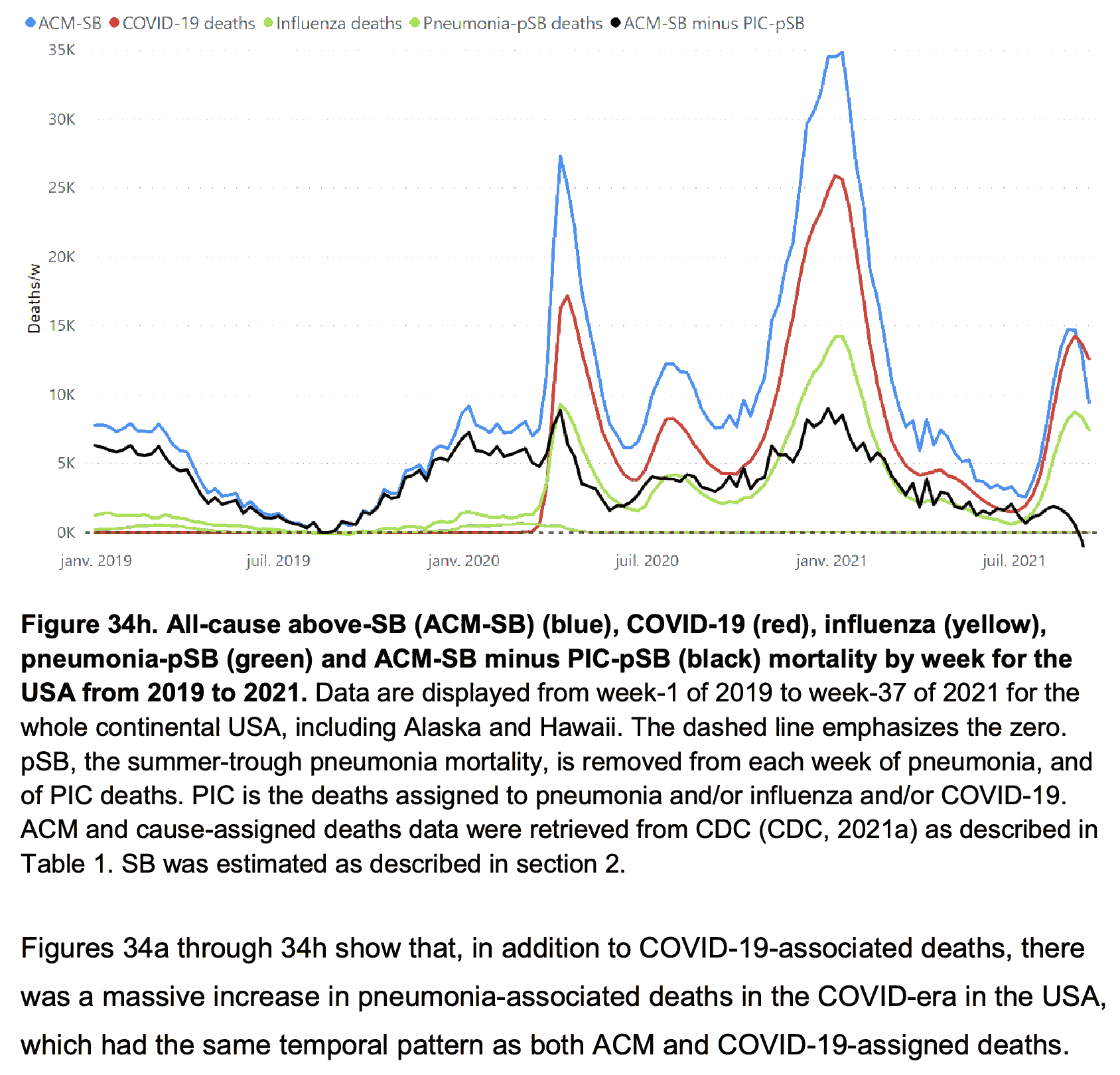
In December 2024 Rancourt published a paper titled "Medical Hypothesis: Respiratory epidemics and pandemics
without viral transmission".
[https://correlation-canada.org/respiratory-epidemics-without-viral-transmission/]
In the paper he wrote: "Rancourt et al. (2021a)
showed this in detail, into 2021 (their Figures 34a through 34i). They
also pointed out that more than half of the deaths assigned as COVID-19
deaths could include life-threatening co-occurring bacterial pneumonia,
according to CDC tabulations of death certificates, and that
prescriptions of antibiotics were significantly reduced in the same
period."
The figures from his old paper showed data from CDC WONDER, where
during COVID waves the number of deaths with MCD pneumonia was about
half or more of the number of deaths with MCD COVID:
[http://researchgate.net/publication/355574895]
The figures included various forms of pneumonia and not only
bacterial pneumonia, even though the paper didn't seem to specify which
ICD codes were included under the label of pneumonia.
The death record data used at CDC WONDER can be downloaded from here:
https://cdc.gov/nchs/nvss/mortality_public_use_data.htm.
In the files for 2020-2022, about 51% of deaths with UCD U07.1 have MCD
J18.9 (pneumonia, unspecified), which is by far the most common MCD for
deaths with UCD COVID. The most common MCD for specifically bacterial
pneumonia is J15.9 (Bacterial pneumonia, unspecified), which is only
included for about 1.2% deaths with UCD COVID, followed by J15.2
(Pneumonia due to staphylococcus, 0.5%), J15.1 (Pneumonia due to
Pseudomonas, 0.3%), and J15.0 (Pneumonia due to Klebsiella pneumoniae,
0.1%):
100.0 73.5 U071 COVID-19
50.7 72.7 J189 Pneumonia, unspecified
25.3 72.8 J960 Acute respiratory failure
16.3 72.8 J969 Respiratory failure, unspecified
15.1 75.6 I10 Essential (primary) hypertension
11.7 71.8 I469 Cardiac arrest, unspecified
10.9 67.5 J80 Adult respiratory distress syndrome
[...]
3.0 73.3 J129 Viral pneumonia, unspecified
[...]
1.2 71.9 J159 Bacterial pneumonia, unspecified
[...]
1.0 78.5 J690 Pneumonitis due to food and vomit
[...]
0.6 69.3 A499 Bacterial infection, unspecified
[...]
0.5 64.4 J152 Pneumonia due to staphylococcus
[...]
0.3 66.1 J151 Pneumonia due to Pseudomonas
[...]
0.2 68.5 A498 Other bacterial infections of unspecified site
[...]
0.2 72.6 J181 Lobar pneumonia, unspecified
[...]
0.2 69.4 J180 Bronchopneumonia, unspecified
[...]
0.1 64.7 J150 Pneumonia due to Klebsiella pneumoniae
[...]
0.1 72.8 J128 Other viral pneumonia
There's a total of 954,269 records with UCD COVID but only 21,350
records had any of the ICD codes that specifically designate bacterial
pneumonia (J13-J15). There's of course a lot of people who had the MCD
for unspecified pneumonia even though they actually had bacterial
pneumonia or pneumonia that was due to a bacterial coinfection along
with SARS-CoV-2.
But in any case pneumonia is a symptom of COVID itself, so the
looking at the prevalence of any form of pneumonia among people who died
from COVID is not a reasonable way to estimate the prevalence of
bacterial pneumonia among people who died from COVID.
Here's the causes of death listed for 5 random people with UCD COVID,
where you can see that all 5 people had some additional
respiratory-related MCD besides COVID:
CDC's guidelines for filling a COVID death certificate say: "Intermediate causes are those conditions that typically
have multiple possible underlying etiologies and thus, a UCOD must be
specified on a line below in Part I. For example, pneumonia is an
intermediate cause of death since it can be caused by a variety of
infectious agents or by inhaling a liquid or chemical. Pneumonia is
important to report in a cause-of-death statement but, generally, it is
not the UCOD. The cause of pneumonia, such as COVID-19, needs to be
stated on the lowest line used in Part I."
[https://www.cdc.gov/nchs/data/nvss/vsrg/vsrg03-508.pdf]
The same CDC document also says: "If COVID-19 played
a role in the death, this condition should be specified on the death
certificate. In many cases, it is likely that it will be the UCOD, as it
can lead to various life-threatening conditions, such as pneumonia and
acute respiratory distress syndrome (ARDS). In these cases, COVID-19
should be reported on the lowest line used in Part I with the other
conditions to which it gave rise listed on the lines above
it."
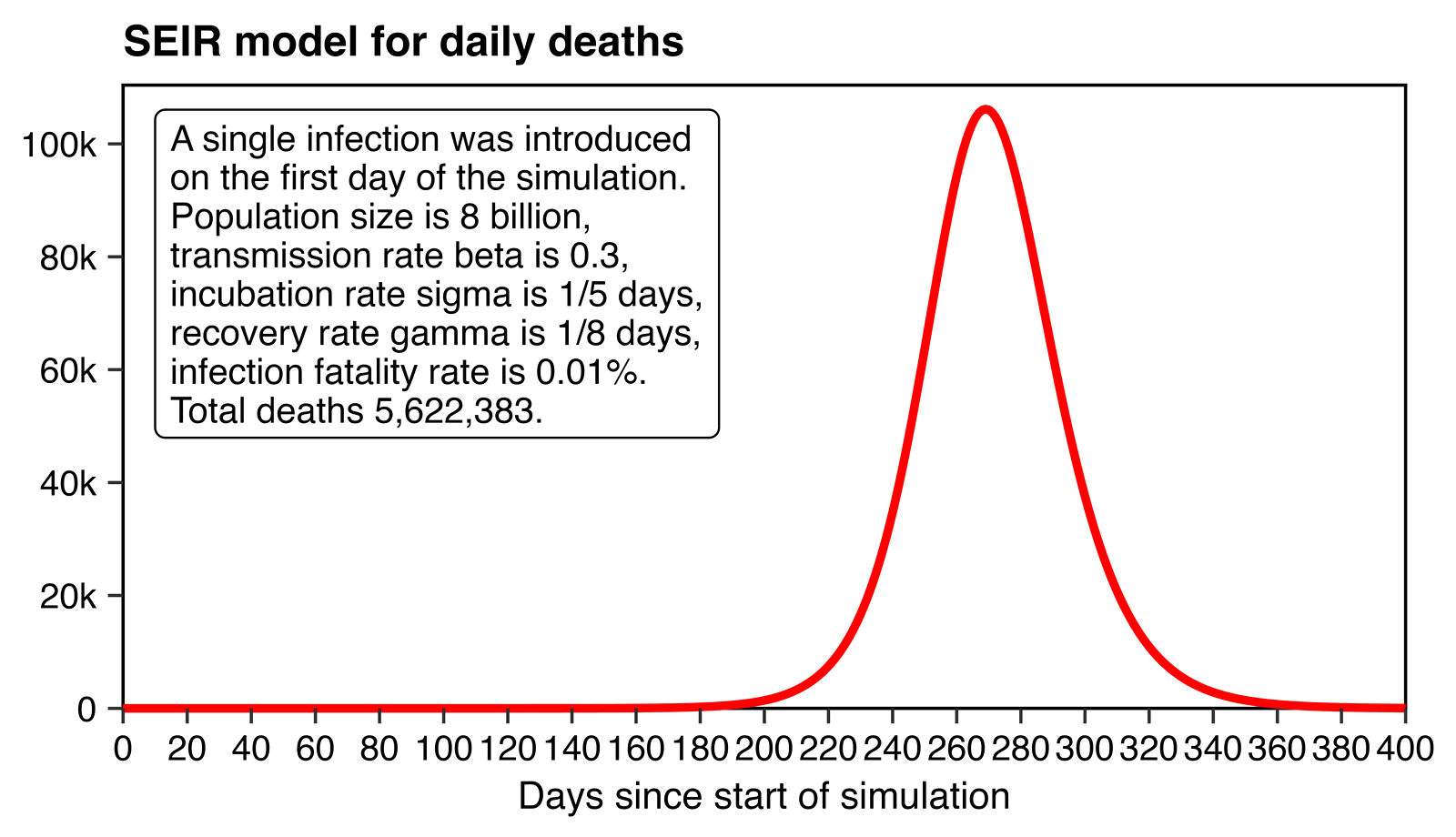
I posted this plot to him and asked that if you make a SEIR model
with parameters similar to the COVID pandemic in 2020, then if you
introduce a single infection in October 2019 then how long does it take
for the deaths to rise clearly above zero relative to the eventual peak
in deaths?
library(deSolve);library(ggplot2)
seir=\(time,state,parameters){
with(as.list(c(state,parameters)),{
dS<--beta*S*I/N
dE=beta*S*I/N-sigma*E
dI=sigma*E-gamma*I
dR=gamma*I
dD=death_rate*I # deaths are a fraction of infected
list(c(dS,dE,dI,dR,dD))
})
}
N=8e9 # population size
beta=0.3 # transmission rate
sigma=1/5 # incubation period 5 days
gamma=1/8 # infectious period 8 days
death_rate=.0001 # infection fatality rate 0.01%
xstart=0;xend=400;xstep=20;days=0:xend
init=c(S=N-1,E=0,I=1,R=0,D=0)
par=c(beta=beta,sigma=sigma,gamma=gamma,death_rate=death_rate,N=N)
p=as.data.frame(ode(y=init,times=days,func=seir,parms=par))
p$dead=diff(c(0,p$D))
sub=paste0("A single infection was introduced
on the first day of the simulation.
Population size is 8 billion,
transmission rate beta is 0.3,
incubation rate sigma is 1/5 days,
recovery rate gamma is 1/8 days,
infection fatality rate is 0.01%.
Total deaths ",formatC(sum(p$dead),digits=0,format="f",big.mark=","),".")
ybreak=pretty(p$dead);ystart=0;yend=max(p$dead)*1.04
ggplot(p,aes(x=time,y=dead))+
geom_vline(xintercept=c(xstart,xend),lineend="square",linewidth=.3)+
geom_hline(yintercept=c(ystart,yend),lineend="square",linewidth=.3)+
geom_line(color="red",linewidth=.8)+
annotate(geom="label",label=sub,x=10,y=77e3,fill="white",label.r=unit(2,"pt"),label.padding=unit(3,"pt"),label.size=.2,size=2.5,hjust=0,lineheight=.9)+
labs(x="Days since start of simulation",y=NULL,title="SEIR model for daily deaths")+
scale_x_continuous(limits=c(xstart,xend),breaks=seq(xstart,xend,xstep))+
scale_y_continuous(limits=c(ystart,yend),breaks=ybreak,labels=kim)+
coord_cartesian(clip="off",expand=F)+
theme(axis.text=element_text(size=7,color="black"),
axis.ticks=element_line(linewidth=.3),
axis.ticks.length=unit(3,"pt"),
axis.title=element_text(size=7.5),
panel.background=element_blank(),
panel.grid=element_blank(),
plot.margin=margin(4,10,4,4,"pt"),
plot.title=element_text(face=2,size=8.4,margin=margin(1,,4)))
ggsave("1.png",width=4,height=2.3,dpi=400*4)
system("magick 1.png -resize 25% PNG8:1.png")
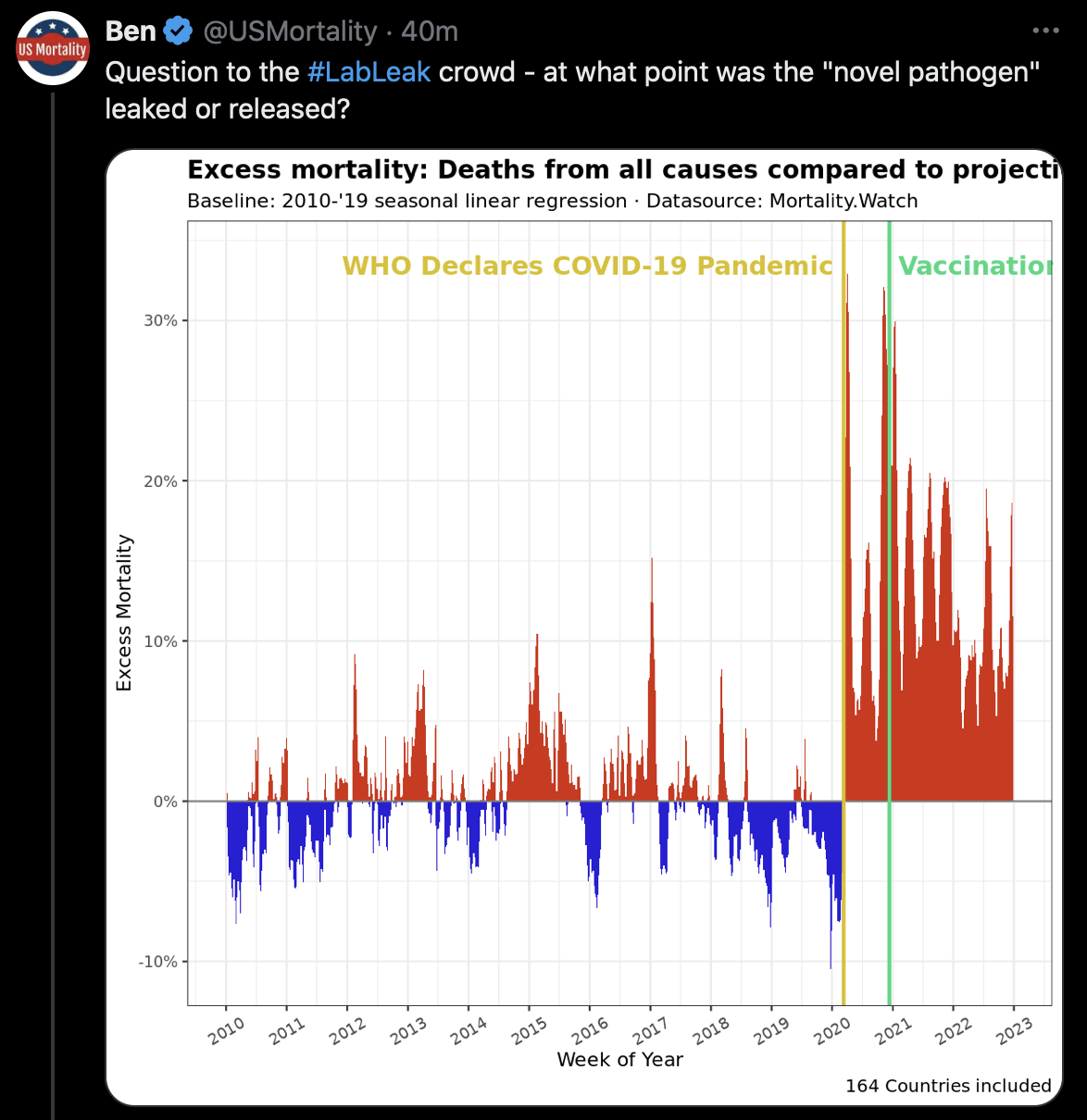
Some people from the no-pandemic crowd have made claims like that
there were no excess deaths anywhere in the world before the day of the
WHO pandemic declaration. USMortality probably knows better because he
has done a lot of work aggregating worldwide mortality data. But I
pointed out to him anyway that in Bergamo the deaths had already reached
about halfway up to the peak on the day of the WHO pandemic
declaration:
USMortality told me: "It's almost impossible for
a single point emergence to cause peaks in the exact same week all over
the world!" But I pointed out that the peak in deaths was not
even close to the same week all over the world, and I posted this plot
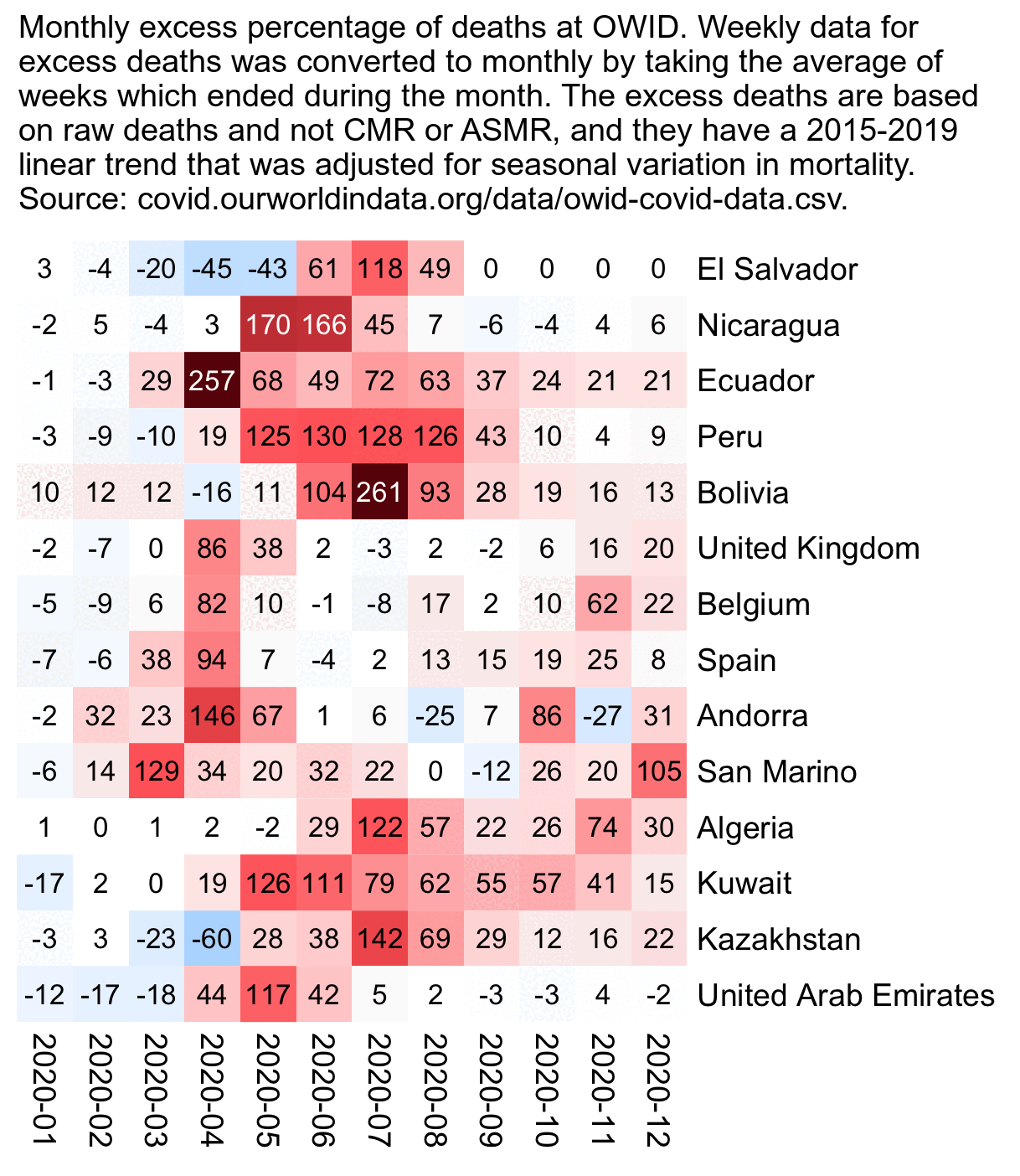
of countries with at least 80% monthly excess deaths at OWID in
2020:
download.file("https://covid.ourworldindata.org/data/owid-covid-data.csv","owid-covid-data.csv")
download.file("https://gist.githubusercontent.com/tadast/8827699/raw/61b2107766d6fd51e2bd02d9f78f6be081340efc/countries_codes_and_coordinates.csv","latlongiso3.csv")
library(data.table)
yemo=\(x){u=unique(x);format(u,"%Y-%m")[match(x,u)]}
t=fread("owid-covid-data.csv")
lat=r("f/countrylatlongiso3")[,.(iso_code=`Alpha-3 code`,lat=`Latitude (average)`,long=`Longitude (average)`)]
t=merge(t,lat)
o[,continent:=factor(continent,c("North America","South America","Europe","Africa","Asia"))]
a=o[date<="2020-12-31",.(excess=mean(excess_mortality,na.rm=T)),.(location,month=yemo(date),lat,long,continent)]
a=a[location%in%a[excess>=80,location]]
a[,location:=factor(location,a[rowid(location)==1,location[order(continent,-lat+long)]])]
m=a[,xtabs(excess~location+month)]
disp=round(m)
maxcolor=max0(m)
pal=colorRampPalette(hex(HSV(c(210,210,210,210,0,0,0,0,0),c(.9,.75,.6,.3,0,.3,.6,.75,.9),c(.4,.65,1,1,1,1,1,.65,.4))))(256)
pheatmap::pheatmap(m,filename="0.png",display_numbers=disp,
cluster_rows=F,cluster_cols=F,legend=F,cellwidth=16,cellheight=16,fontsize=9,fontsize_number=8,
border_color=NA,na_col="gray90",
number_color=ifelse(abs(m)>maxcolor*.6,"white","black"),
breaks=seq(-maxcolor,maxcolor,,256),
pal)
sub="Monthly excess percentage of deaths at OWID. Weekly data for excess deaths was converted to monthly by taking the average of weeks which ended during the month. The excess deaths are based on raw deaths and not CMR or ASMR, and they have a 2015-2019 linear trend that was adjusted for seasonal variation in mortality. Source: covid.ourworldindata.org/data/owid-covid-data.csv."
system(paste0("mar=22;w=`identify -format %w 0.png`;convert \\( -size $[w-mar*2]x -font Arial -interline-spacing -3 -pointsize 38 caption:'",sub,"' -splice $[mar]x10 \\) 0.png -append 1.png"))
In China reported COVID deaths already peaked around
mid-February:
cases=fread("https://github.com/cheongsa/Coronavirus-COVID-19-statistics-in-China/raw/master/China_daily_new_infections.csv",header=T)
dead=fread("https://github.com/cheongsa/Coronavirus-COVID-19-statistics-in-China/raw/master/China_daily_new_deaths.csv",header=T)
m=as.matrix(rowsum(cases[,-(1:4)],cases[[2]]))
m[is.na(m)]=0
colnames(m)=sub(" .*","",colnames(m))
rownames(m)=sub(" (Uygur |Zhuang |Hui )?(Autonomous Region|Special Administrative Region|Municipality)","",rownames(m))
m=rbind(m,"Total cases"=colSums(m),"Deaths (Hubei)"=colSums(dead[dead$Pro=="Hubei",-(1:4)],na.rm=T),"Total deaths"=colSums(dead[,-(1:4)],na.rm=T))
disp=ifelse(m>=1e4,sprintf("%.0fk",m/1e3),ifelse(m>=1e3,sprintf("%.1fk",m/1e3),m))
max=apply(m,1,max,na.rm=T)
max[is.infinite(max)]=NA
m=m/max
pheatmap::pheatmap(m,filename="1.png",display_numbers=disp,gaps_row=nrow(m)-3,
cluster_rows=F,cluster_cols=F,legend=F,cellwidth=16,cellheight=13,fontsize=9,fontsize_number=8,
border_color=NA,na_col="gray90",number_color=ifelse(!is.na(m)&m>.45,"white","black"),
breaks=seq(0,1,,256),sapply(255:0/255,\(i)rgb(i,i,i)))
system("w=`identify -format %w 1.png`;convert \\( -size $[w-44]x -pointsize 40 -font Arial caption:'COVID cases in China (github.com/cheongsa/Coronavirus-COVID-19-statistics-in-China). Each row has its own color scale where the maximum value is shown in black. On February 12th Hubei health authorities began including clinically diagnosed cases, such as cases with a chest CT scan showing signs of pneumonia even if a positive PCR test was not available, so many cases and deaths were added retroactively.' -splice 22x20 \\) 1.png -append 1.png")
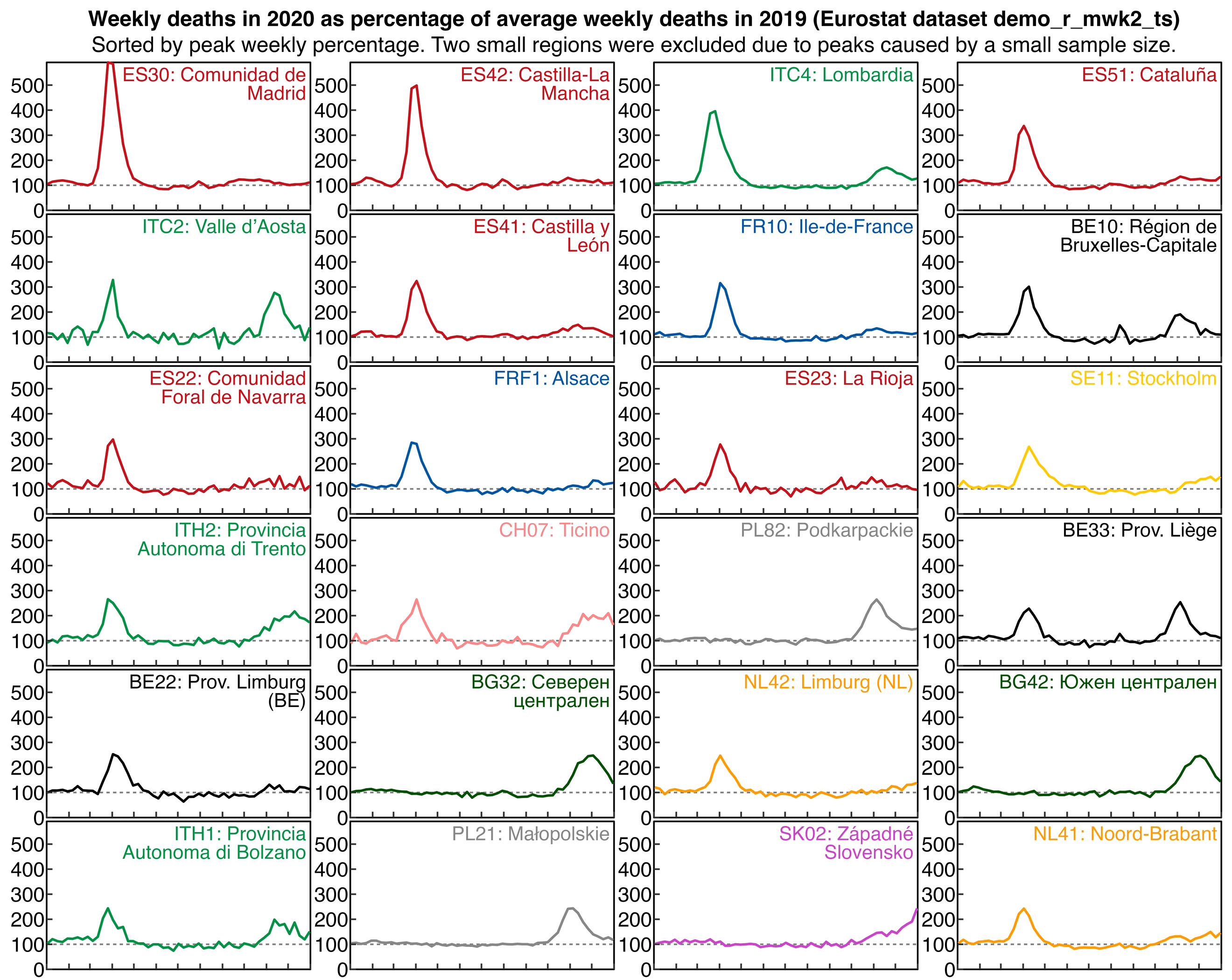
Bergamo is a NUTS3-level region within Lombardy which is a
NUTS2-level region. On Eurostat when I sorted NUTS2 regions by the peak
weekly excess deaths in 2020, the two highest-ranking regions were
Madrid and Castilla-La Mancha which are both in central Spain, and
Lombardy only came on third place:
download.file("https://ec.europa.eu/eurostat/api/dissemination/sdmx/2.1/data/demo_r_mwk3_t?format=TSV","demo_r_mwk3_t.tsv")
download.file("https://ec.europa.eu/eurostat/api/dissemination/sdmx/2.1/data/demo_r_mwk2_ts?format=TSV","estat_demo_r_mwk2_ts.tsv")
download.file("https://ec.europa.eu/eurostat/documents/345175/629341/NUTS2021.xlsx","NUTS2021.xlsx")
library(data.table);library(ggplot2);library(readxl)
ua=\(x,y,...){u=unique(x);y(u,...)[match(x,u)]}
isoweek=\(year,week,weekday=7){d=as.Date(paste0(year,"-1-4"));d-(as.integer(format(d,"%w"))+6)%%7-1+7*(week-1)+weekday}
nuts=setDT(read_excel("NUTS2021.xlsx",sheet=2))
nuts=na.omit(nuts[,.(name=unlist(.SD[,2:4],,F),nuts=.SD[[1]])])[!name%like%"Extra-Regio"]
euro=fread("estat_demo_r_mwk2_ts.tsv",na=":")
euro=euro[euro[[1]]%like%"^W,T"]
eu=melt(euro,id=1,,"week","dead")
eu[,week:=ua(week,\(x)isoweek(as.integer(substr(x,1,4)),as.integer(substr(x,7,8)),4))]
eu=eu[,.(nuts=sub(".*,","",eu[[1]]),dead=as.integer(sub(" .*","",dead)),week)]
eu=merge(eu[year(week)==2019,.(base=mean(dead)),nuts],eu)
eu=merge(nuts,eu)
eu[,name:=paste0(nuts,": ",sub("/.*","",name))]
eu=eu[!nuts%like%"LI00|ES64"&nchar(nuts)==4]
pick=eu[year(week)==2020,max(dead/base),nuts][order(-V1)][1:24,nuts]
p=eu[nuts%in%pick][,nuts:=factor(nuts,pick)]
p[,pct:=dead/base*100]
xstart=as.Date("2020-1-1");xend=as.Date("2021-1-1");xbreak=seq(xstart,xend,"month")
p=p[week>=xstart&week<=xend]
colors=fread("country,color
ES,c6111a
IT,009246
FR,0055a4
BE,000000
SE,ffcd00
CH,ff8888
PL,888888
BG,005000
NL,ff9b00
SK,cc44cc
LI,8888ff")
p[,country:=factor(substr(nuts,1,2),colors$country)]
ggplot(p)+
facet_wrap(~nuts,ncol=4,strip.position="top",scales="free")+
geom_hline(yintercept=100,linetype="22",linewidth=.4,color="gray50")+
annotate("rect",xmin=xstart,xmax=xend,ymin=0,ymax=yend,linewidth=.4,lineend="square",linejoin="mitre",fill=NA,color="black")+
geom_line(aes(week,pct,color=country),linewidth=.6)+
geom_label(data=p[rowid(nuts)==1],aes(xend-3,yend*.98,label=str_wrap(name,20),color=country),hjust=1,vjust=1,fill=alpha("white",.85),label.r=unit(0,"pt"),label.padding=unit(1,"pt"),label.size=0,size=3.5,lineheight=.8)+
labs(title="Weekly deaths in 2020 as percentage of average weekly deaths in 2019 (Eurostat dataset demo_r_mwk2_ts)",subtitle="Sorted by peak weekly percentage. Two small regions were excluded due to peaks caused by a small sample size.",x=NULL,y=NULL)+
scale_x_continuous(limits=c(xstart,xend),breaks=xbreak)+
scale_y_continuous(breaks=pretty(p$pct))+
scale_color_manual(values=paste0("#",colors$color))+
coord_cartesian(clip="off",expand=F)+
theme(axis.text=element_text(size=10.5,color="black"),
axis.text.x=element_blank(),
axis.text.y=element_text(margin=margin(,1)),
axis.ticks=element_line(linewidth=.4),
axis.ticks.length=unit(-3,"pt"),
legend.position="none",
panel.background=element_blank(),
panel.spacing.x=unit(2,"pt"),
panel.spacing.y=unit(2,"pt"),
plot.subtitle=element_text(hjust=.5,margin=margin(,,3)),
plot.title=element_text(size=11,face="bold",hjust=.5,margin=margin(,,3)),
strip.background=element_blank(),
strip.text=element_blank())
ggsave("1.png",width=8.8,height=7,dpi=300*4)
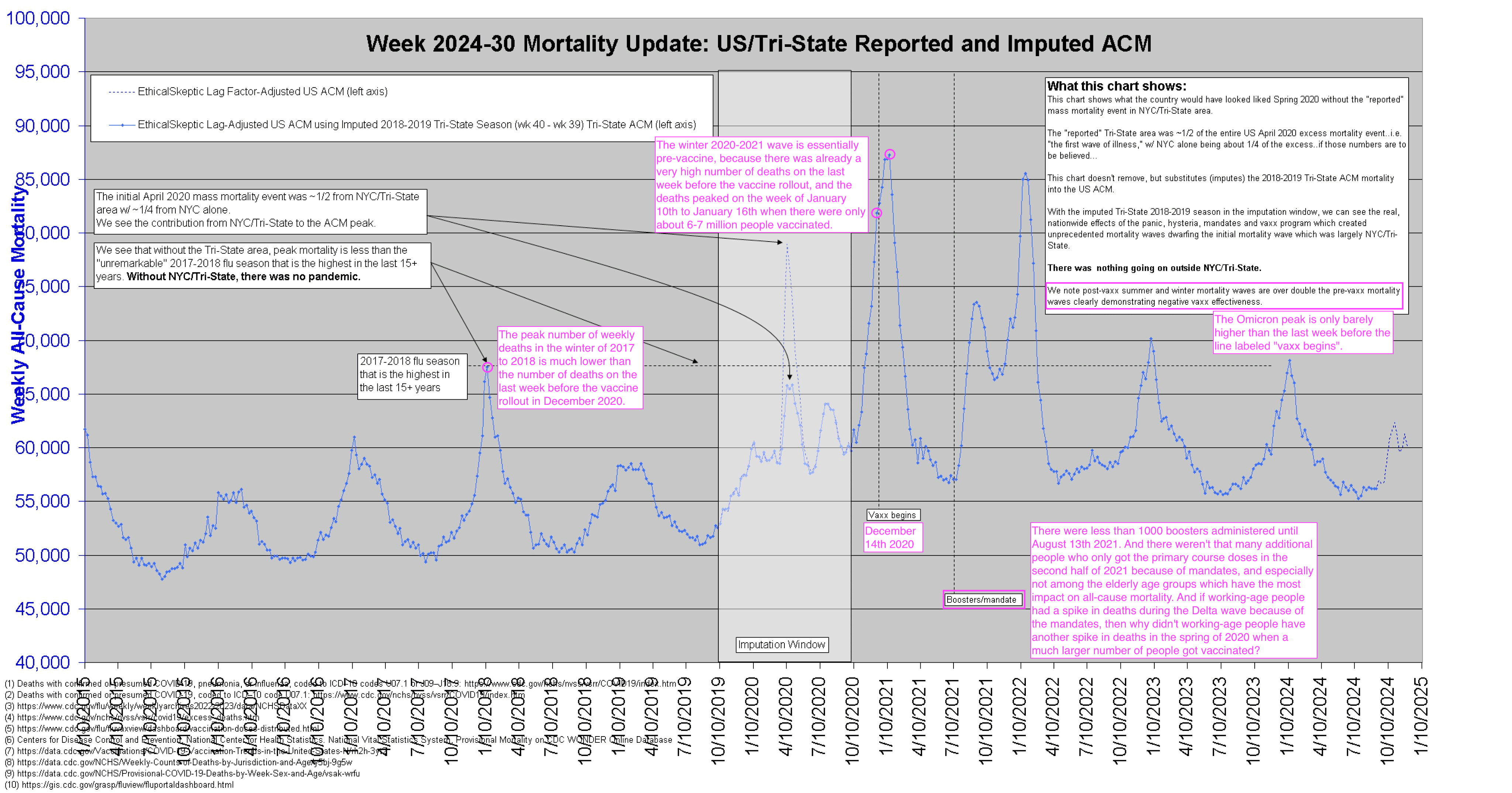
As it turns out, outside of NYC/Tri-State, those numbers are pretty
close.
There were ~100K excess deaths spring 2020. ~1/2 of them were
Tri-State. ~1/4 were NYC alone.
Not even close to 2017-2018 "flu
season."
The real mortality didn't start until the jabs, and really took off
with the boosters.
And he posted this image without my notes in magenta, where my notes
show how the number of deaths on the first week before the vaccine
rollout was almost as high as deaths during the Omicron peak, and it was
much higher than the number of deaths during the peak in the winter of
2017-2018:
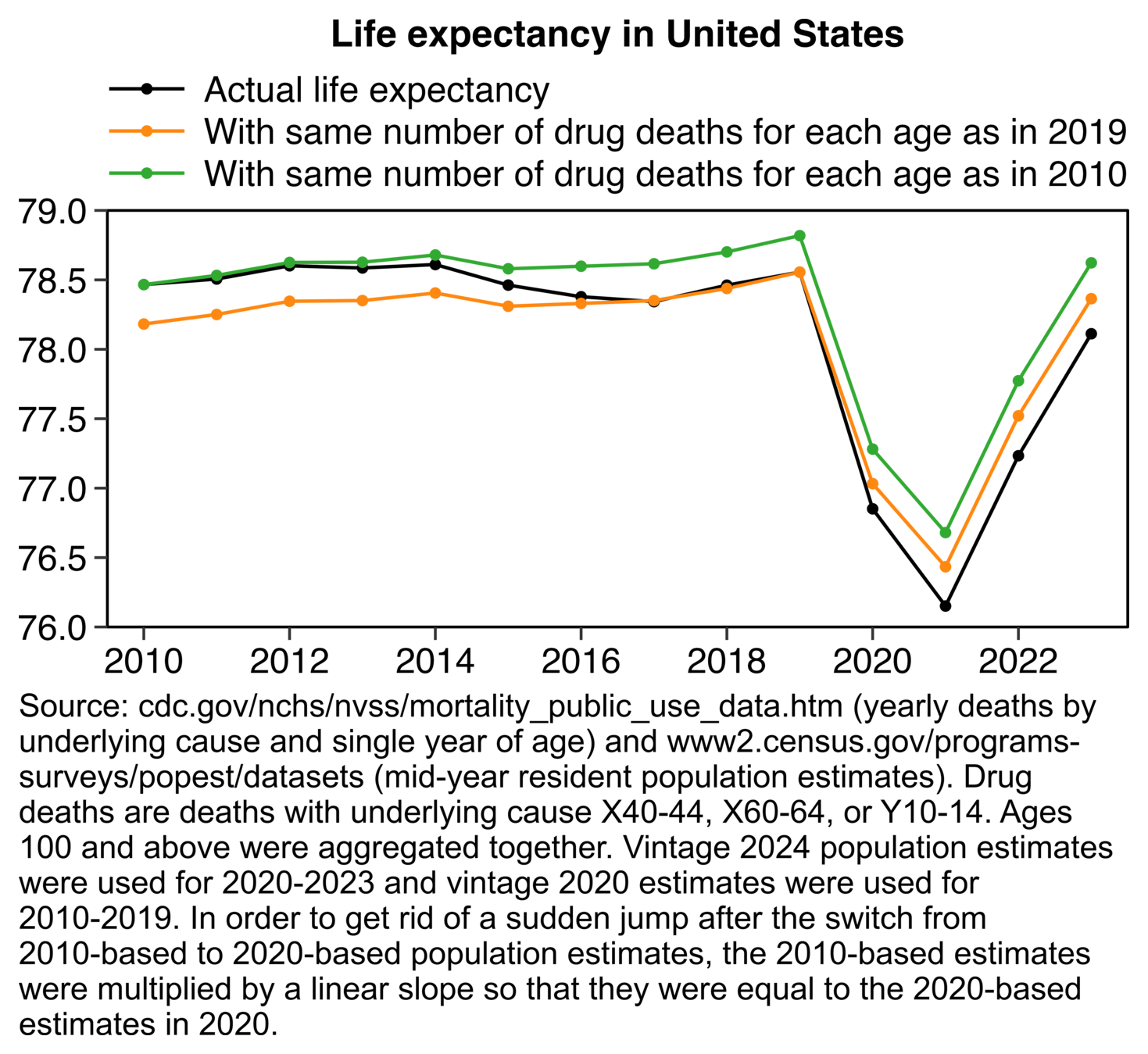
Housatonic has been saying that the only reason why US life
expectancy has gone down since 2020 is because of extra deaths from drug
overdoses.
However I calculated that the reduction in life expectancy between
2019 and 2021 was about 2.4 years. But when I replaced the number of
drug deaths for each age with the number of drug deaths in 2019, it only
increased the life expectancy in 2021 by about 0.3 years. So the extra
drug deaths accounted for only about 12% of the reduction in life
expectancy between 2019 and 2021:
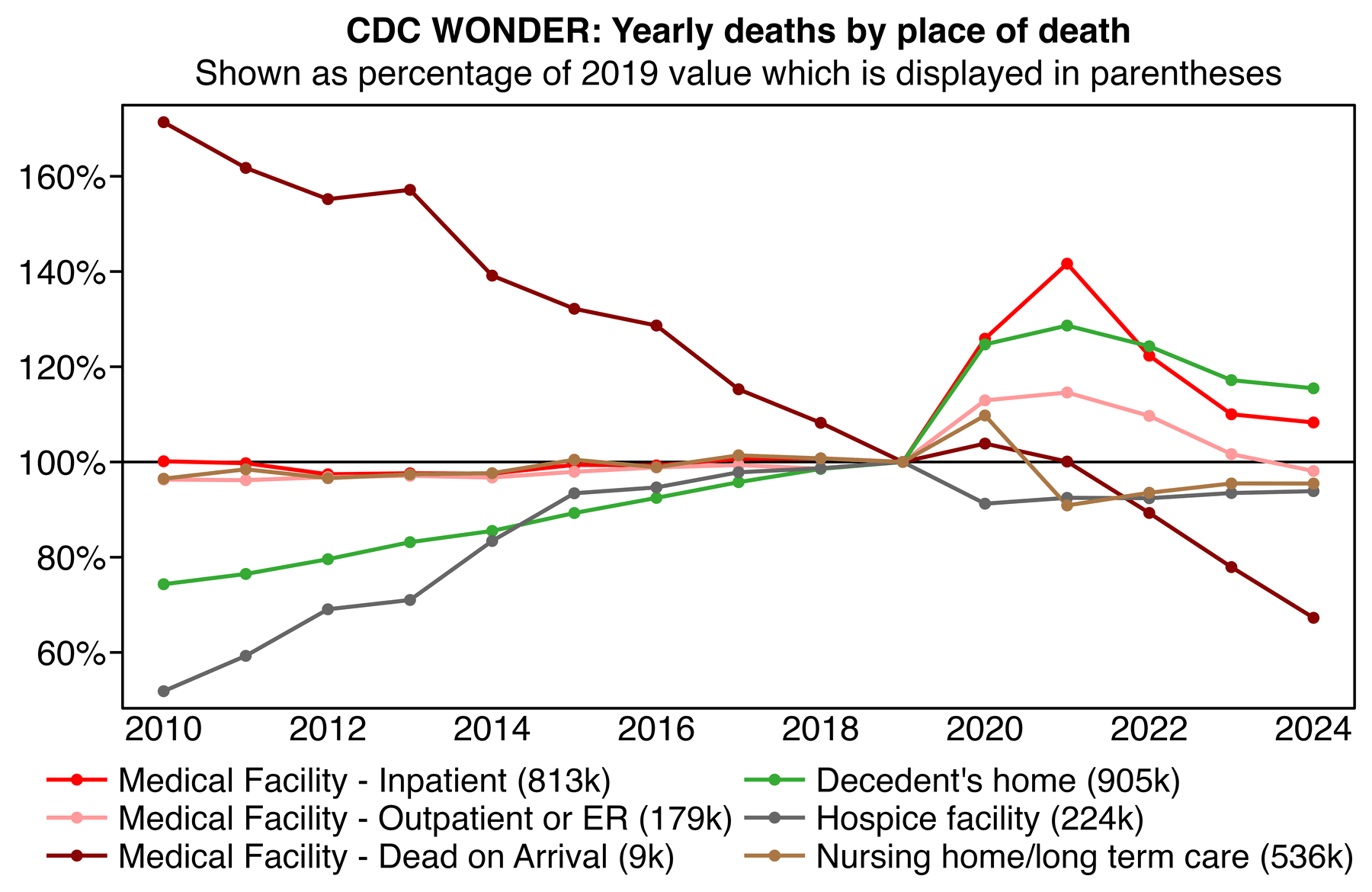
The results show that the number of deaths where the place of death
was listed as decedent's home increased from about 0.90 million in 2019
to about 1.13 million in 2020. How is it possible if people were not
really dying of COVID, but the excess deaths in 2020 were due to
hospital protocols?
This plot also shows that the number of deaths where the place of
death was listed as the decendent's home was about 25% higher in 2020
than 2019:
t=fread("https://sars2.net/f/wonderplacedeath.csv")[year<2025&!place%like%"unknown|Other"]
t=t[place%in%place[year==2019]]
t[,place:=factor(place,t[rowid(place)==1,place[order(placecode)]])]
p=merge(t[year%in%2019,.(mean=mean(dead)),place],t)
levels(p$place)=p[rowid(place)==1,sprintf("%s (%.0fk)",place,mean/1e3)]
p=p[,.(x=year,y=dead/mean*100,z=place)]
xstart=2010;xend=2024;xbreak=seq(xstart,xend,2)
p=p[x%in%xstart:xend]
ylim=extendrange(p$y,,.03);ybreak=pretty(ylim,7)
ggplot(p,aes(x,y))+
geom_hline(yintercept=100,linewidth=.4)+
geom_line(aes(color=z),linewidth=.6)+
geom_point(aes(color=z),size=1.1)+
labs(x=NULL,y=NULL,title="CDC WONDER: Yearly deaths by place of death",subtitle="Shown as percentage of 2019 value which is displayed in parentheses")+
scale_x_continuous(limits=c(xstart-.5,xend+.5),breaks=xbreak)+
scale_y_continuous(limits=ylim,breaks=ybreak,labels=\(x)paste0(x,"%"))+
scale_color_manual(values=c("#ff0000","#ff9999","#880000","#33aa33","gray40","#aa7744","gray80"))+
coord_cartesian(clip="off",expand=F)+
guides(color=guide_legend(ncol=2,byrow=F))+
theme(axis.text=element_text(size=11,color="black"),
axis.text.y=element_text(margin=margin(,1)),
axis.ticks=element_line(linewidth=.4,color="black"),
axis.ticks.length.x=unit(0,"pt"),
axis.ticks.length.y=unit(4,"pt"),
legend.background=element_blank(),
legend.box.spacing=unit(0,"pt"),
legend.justification="right",
legend.key=element_blank(),
legend.key.height=unit(12,"pt"),
legend.key.width=unit(24,"pt"),
legend.margin=margin(4),
legend.position="bottom",
legend.spacing.x=unit(1,"pt"),
legend.spacing.y=unit(0,"pt"),
legend.text=element_text(size=10.6),
legend.title=element_blank(),
panel.background=element_blank(),
panel.border=element_rect(fill=NA,linewidth=.4),
plot.subtitle=element_text(size=11,margin=margin(,,4),hjust=.5),
plot.title=element_text(size=11,face=2,hjust=.5,margin=margin(,,3)))
ggsave("1.png",width=6,height=3.9,dpi=300*4)
system("magick 1.png -resize 25% -colors 256 1.png")
In 2020 there were about 200,000 excess deaths that occurred at home
relative to the 2010-2019 linear trend:
The CDC's guidelines for filling COVID deaths certificates say: "If COVID-19 played a role in the death, this condition
should be specified on the death certificate. In many cases, it is
likely that it will be the UCOD, as it can lead to various
life-threatening conditions, such as pneumonia and acute respiratory
distress syndrome (ARDS). In these cases, COVID-19 should be reported on
the lowest line used in Part I with the other conditions to which it
gave rise listed on the lines above it."
[https://www.cdc.gov/nchs/data/nvss/vsrg/vsrg03-508.pdf]
The CDC has published fixed-width text files that contain one line
for each person who died in the United States. You can use the files to
see the full cause of death list of each person who died with the
underlying cause COVID.
[rootclaim3.html#Were_about_half_of_COVID_deaths_incorrectly_attributed_to_COVID]
A typical record might look like this, where COVID led to pneumonia
which led to respiratory failure:
Line 1: J96.0 - Acute respiratory failure (immediate cause)
Line 2: J18.9 - Pneumonia, unspecified (intermediate cause)
Line 3: U07.1 - COVID-19 (underlying cause)
There are 66 death records in 2021 with the underlying cause Y59.0
("Viral vaccines").
[rootclaim3.html#Yearly_deaths_at_NVSS_with_underlying_cause_possibly_related_to_vaccination]
However all of the records also include some other cause of death, like
T88.1 (Other complications following immunization, not elsewhere
classified) or T80.5 (Anaphylactic shock due to serum). So does that
mean that there were zero deaths that were caused by vaccines alone?
There were 10 records that listed hypertension as a cause of death.
So if someone had hypertension then was it impossible for them to die
from a vaccine alone? There were 8 records that included the code for
cardiac arrest, which is often listed as the immediate cause of death
for various underlying causes of death (since cardiac arrest means
stopping of the heart, which is a rather universal feature of
death):
ua=\(x,y,...){u=unique(x);y(u,...)[match(x,u)]}
dotcode=\(x)ifelse(x%like%"^ ",substr(x,2,4),sub("(...)(.)","\\1.\\2",x))
l[,code:=ua(code,dotcode)]
icd=fread("https://sars2.net/f/wondericd.csv")[,setNames(cause,code)]
s[,.(count=.N),.(code,name=icd[code])][order(-count)][1:10]
# code name count
# Y59.0 Viral vaccines 66
# T88.1 Other complications following immunization, not... 57
# I10 Essential (primary) hypertension 10
# I46.9 Cardiac arrest, unspecified 8
# I50.0 Congestive heart failure 8
# J96.9 Respiratory failure, unspecified 6
# I25.1 Atherosclerotic heart disease 6
# R68.8 Other specified general symptoms and signs 5
# F17.9 Mental and behavioural disorders due to use of ... 5
# E78.5 Hyperlipidaemia, unspecified 5
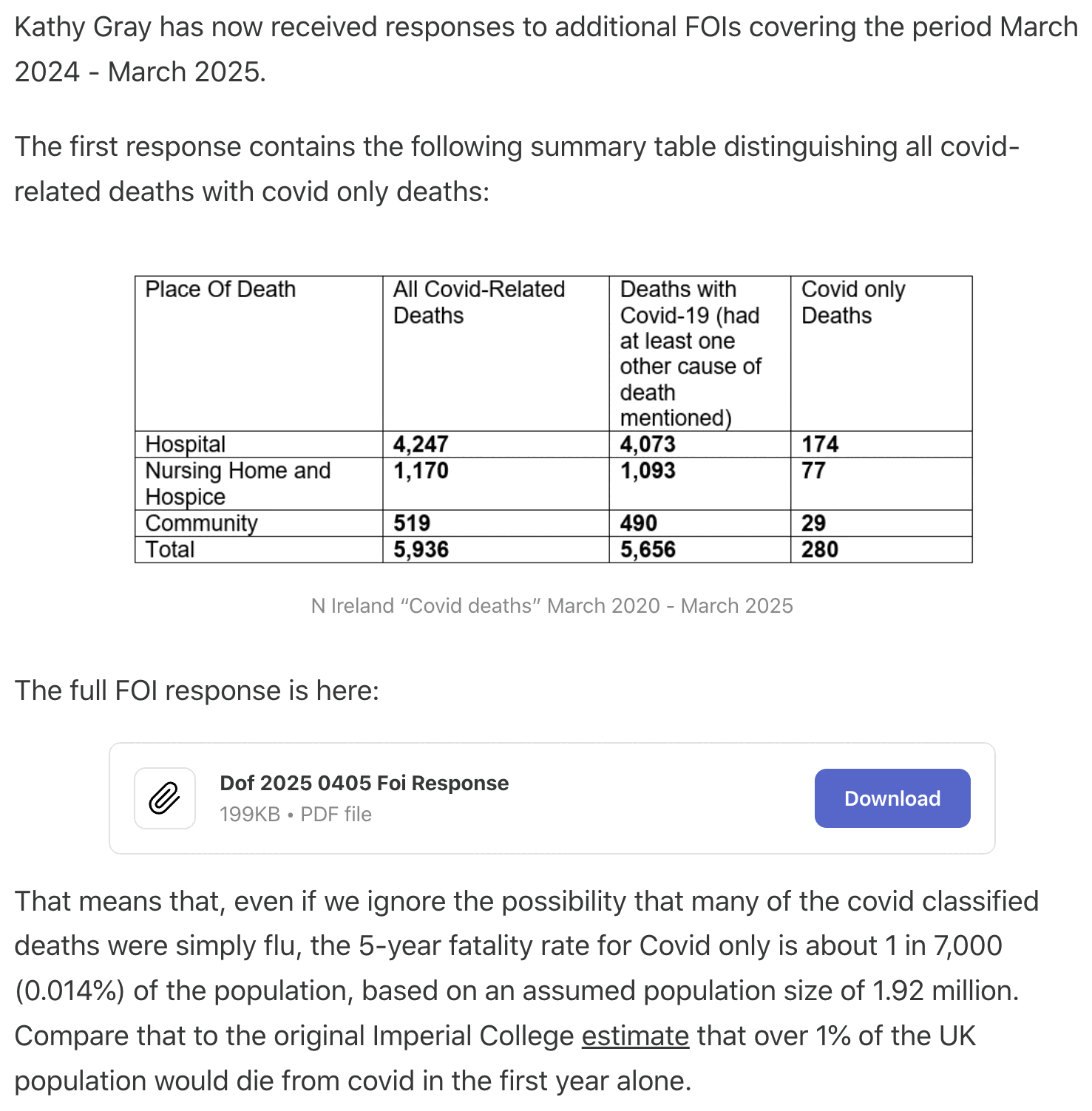
I posted a comment to the Substack post where I pointed out the
issues above, but my comment got deleted. Similar comments were also
posted by canceledmouse and Jessica Hockett, but the authors of the
Substack post have not yet addressed the comments:
Hockett linked to an interview of Robert Anderson, who is the chief
of mortality statistics at National Center for Health Statistics. He
said: "So you have Part One about 'cause of death' section which asks the certifier
to provide the causal sequence. And so you would start on the top line
and you would put the immediate cause of death. To use a COVID-19
example, you might have 'respiratory distress
syndrome' which is a common complication of COVID-19. And then
you would work backwards from that immediate cause of death. And let's
suppose that respiratory distress was brought on by pneumonia, viral
pneumonia, and so you would put on the second line 'viral pneumonia.' And then on the third line -
because we want to know what the cause of viral pneumonia was - if it
was COVID-19, then you would write COVID-19 on the third line. So you'd
have respiratory distress due to viral pneumonia due to COVID-19. That's
a logical causal sequence from the immediate cause working back to the
underlying cause. And then in Part Two, you could put any other
conditions that might have contributed to death but weren't part of that
causal pathway in Part One. Now with a disease like COVID-19, it should
be fairly unusual to see only COVID-19 reported - I mean normally we
should at least see the complications caused by the disease, such as
pneumonia or respiratory distress. In cases where only COVID-19 is
reported, the certifier is indicating that COVID-19 was the cause of
death, but really they left it - the cause of death statement - somewhat
incomplete. They neglected to provide the entire causal pathway. Now
with regard to the other 94% which mentioned other diseases or
conditions, it's important to understand that in the overwhelming
majority of these cases the additional diseases or conditions are either
complications of COVID-19 - they are in the causal pathway, like
pneumonia or respiratory distress - or they're reported in Part Two as
contributing conditions. So for about 92% of the deaths involving
COVID-19 that mention other conditions - 91 or 92% - the certifiers
indicated that COVID-19 is the primary or underlying cause. This is not
a situation where the certifier is writing all of the diseases that the
person had equally; they're actually reporting it in this causal
sequence. And in the overwhelming majority of cases, COVID-19 has been
indicated as the cause of the death. It's the cause that started that
causal pathway, that causal sequence leading to death."
[https://web.archive.org/web/20210320054146/https://www.cdc.gov/nchs/pressroom/podcasts/2021/20210312/20210312.htm]


{kind=link}