
Other parts: czech.
The Czech Ministry of Health has published data for COVID deaths and
hospitalizations by age:
https://
In January 2022 the percentage of vaccinated people was about 3% in ages 0-11 and about 43% in ages 12-15:
>b=fread( " http:// sars2. net/ f/ czbucketskeep. csv. gz")[ dose< =1] > agecut=\( x, y) cut( pmax( x, 0), c( y, Inf), paste0( y, c( paste0( "- ", y[- 1]- 1), "+ ")), T, F) > ages=c( 0, 12, 16, 18, 30, 40, 60, 85) > d=b[ month==" 2022- 01",.( alive=sum( alive)),.( age=agecut( age, ages), dose)] > d[,.( vaxpct=round( sum( alive[ dose==1])/ sum( alive)* 100)), age]| > print( r=F) age vaxpct 0- 11 3 12- 15 43 16- 17 62 18- 29 68 30- 39 64 40- 59 74 60- 84 85 85+ 82
In the United States the COVID deaths also peaked progressively later in progressively younger age groups, so COVID deaths peaked in December 2020 or January 2021 in the oldest age groups, in August or September 2021 in intermediate age groups, and in January 2022 in the youngest age groups:
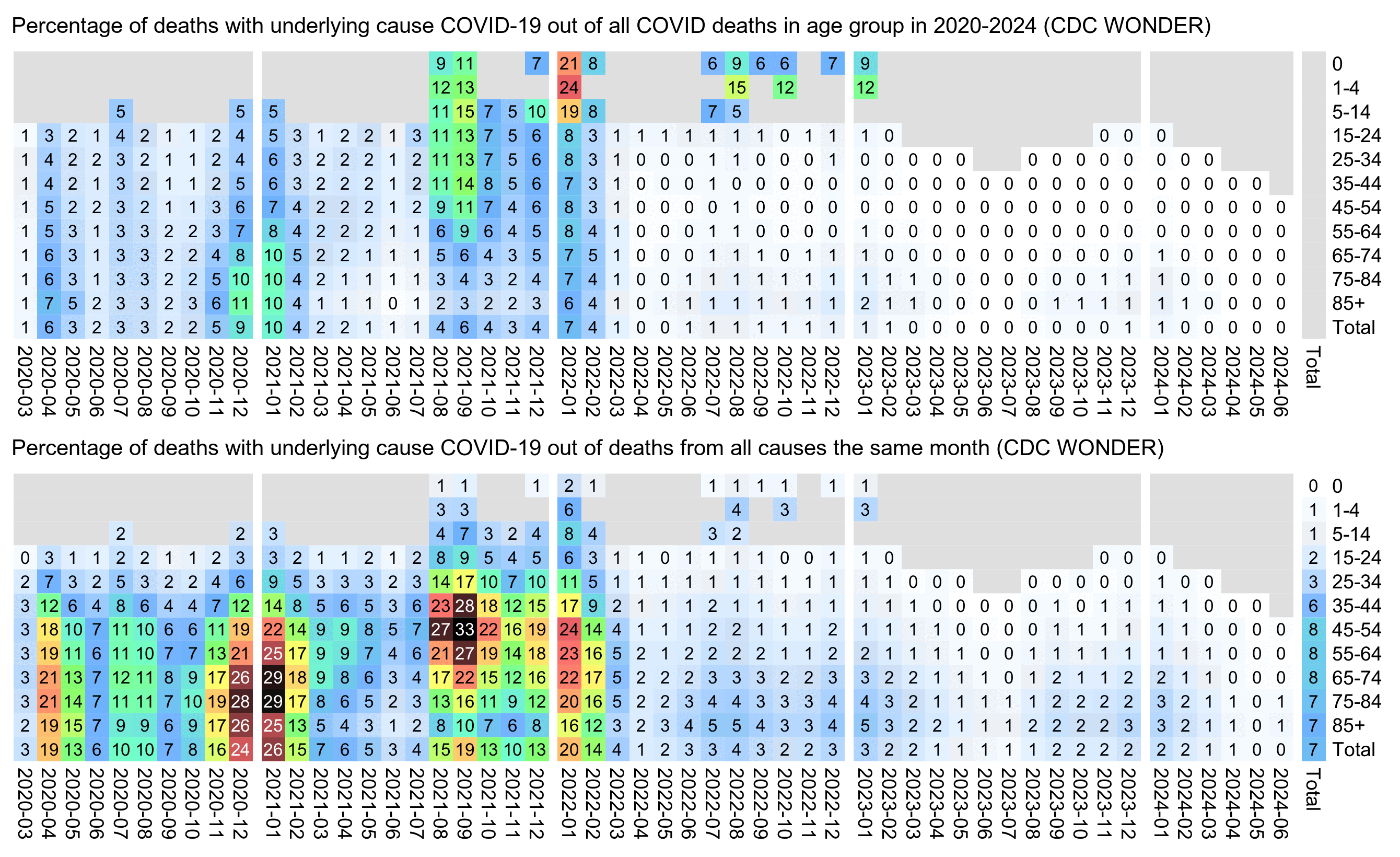
t=fread(" http:// sars2. net/ f/ wondercovidvsall. csv")[ date> =" 2020- 03"] t[, age: =factor( age, unique( age)[ order( as. numeric( unique( sub( "[-+].* ", " ", age))))])] covidall=c( 174, 84, 218, 2375, 10270, 26510, 64828, 144336, 231546, 265489, 267028) t=rbind( t, t[,.( all=sum( all, na. rm=T), date=" Total"), age][, covid: =covidall[ age]]) # t=rbind( t, t[,.( covid=sum( covid, na. rm=T), all=sum( all, na. rm=T), date=" Total"), age]) t=rbind( t, t[,.( covid=sum( covid, na. rm=T), all=sum( all, na. rm=T), age=" Total"), date]) m=tapply( t$ covid, t[, 2: 1], c); m=m/ m[, ncol( m)]* 100; m[, ncol( m)] =NA m2=tapply( t$ covid/ t$ all* 100, t[, 2: 1], c) maxcolor=30 pal=hsv( c( 210, 210, 210, 160, 110, 60, 30, 0, 0, 0)/ 360, c( 0,. 25, rep(. 5, 8)), c( rep( 1, 8),. 5, 0)) gap=c( seq( 10, ncol( m), 12), ncol( m)- 1) pheatmap:: pheatmap( m, filename=" i1. png", display_ numbers=ifelse( is. na( m), " ", round( m)), gaps_ col=gap, cluster_ rows=F, cluster_ cols=F, legend=F, cellwidth=11, cellheight=11, fontsize=9, fontsize_ number=8, border_ color=NA, na_ col=" gray90", number_ color=ifelse( m> maxcolor*. 8&! is. na( m), " white", " black"), breaks=seq( 0, maxcolor,, 256), colorRampPalette( pal)( 256)) pheatmap:: pheatmap( m2, filename=" i2. png", display_ numbers=ifelse( is. na( m2), " ", round( m2)), gaps_ col=gap, cluster_ rows=F, cluster_ cols=F, legend=F, cellwidth=11, cellheight=11, fontsize=9, fontsize_ number=8, border_ color=NA, na_ col=" gray90", number_ color=ifelse( m2> maxcolor*. 8&! is. na( m2), " white", " black"), breaks=seq( 0, maxcolor,, 256), colorRampPalette( pal)( 256)) system( " w=` identify -format %w i1. png`; pad=44; convert -gravity northwest -pointsize 42 -font Arial \\( -splice x24 -size $[ w- pad] x caption: